AudioSep can extract and isolate specific sound components from any mixed audio signal. Unlike traditional sound separation models, AudioSep allows users to specify the sounds they want to separate through natural language descriptions. For example, users can simply enter instructions such as “isolate the piano sound” or “remove background noise.”
AudioSep is designed for open-domain sound separation using natural language queries. It excels at isolating audio events, instruments and enhancing speech.
AudioSep features:
1. Sound separation ability: The core function of AudioSep is to separate specific sounds from complex audio environments, which is very useful in a variety of application scenarios.
2. Natural language query: Unlike traditional sound separation models, AudioSep allows users to specify the sounds they want to separate through natural language descriptions, which greatly improves the flexibility and ease of use of the model. For example, users can simply enter instructions such as “isolate the piano sound” or “remove background noise.”
3. Zero-sample generalization: AudioSep has strong zero-sample generalization capabilities, which means it can perform quite well on unseen, unlabeled data. For example, in a smart home environment, there may be a variety of sound sources (such as televisions, air conditioners, human voices, etc.), and a model capable of zero-sample generalization can more accurately identify and isolate these sounds without having to train each sound separately.
4. Open domain applications: AudioSep is an open domain sound separation model, which means that it is not limited to processing specific types or categories of sound. Whether it’s noise in daily life or specific sounds in professional fields such as medical care, radio, AudioSep has the potential to deal with it.
Projects and demonstrations:https://audio-agi.github.io/Separate-Anything-You-Describe/
Thesis:https://arxiv.org/abs/2308.05037
GitHub:https://github.com/Audio-AGI/AudioSep
HuggingFace demo:https://huggingface.co/spaces/Audio-AGI/AudioSep
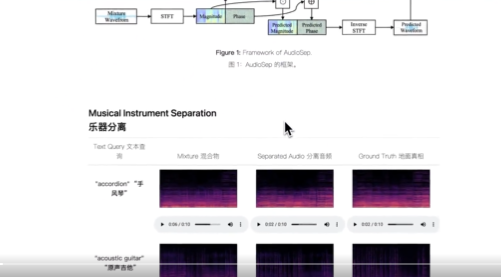
Working principle:
Model architecture:
AudioSep consists of two key components: a text encoder and a sound separation model. The text encoder handles natural language queries and converts them into a fixed-length vector. The sound separation model is responsible for extracting the target sound from the mixed audio.
1. Text coder: This part uses Natural Language Processing (NLP) technology, usually some form of Transformer model, to understand users ‘natural language queries. It encodes text information into a high-dimensional vector.
2. Sound separation model: This part is usually a deep neural network, which receives high-dimensional vectors and mixed audio output by the text encoder as inputs, and then outputs the separated audio.
Data flow and processing:
1. Receive query and audio: When a user proposes a natural language query and a mixed audio, both will be fed into the model.
2. Text encoding: Natural language queries are first processed by a text encoder and converted into a high-dimensional vector.
3. Audio separation: High-dimensional vectors and mixed audio are input into the sound separation model, and the model will output the separated audio.
4. Result output: The user will eventually receive the separated audio. This process can be carried out in real time or offline.
The AudioSep model was extensively evaluated on a variety of tasks, including audio event separation, instrument separation, and speech enhancement. The model demonstrates strong separation performance and impressive zero-sample generalization.