AudioSep可以從任何混合音頻信號中提取和隔離特定的聲音成分。與傳統的聲音分離模型不同,AudioSep允許用戶通過自然語言描述指定他們想要分離的聲音。例如,用戶可以簡單地輸入「隔離鋼琴聲音」或「去除背景噪音」等指令。"
AudioSep旨在使用自然語言查詢進行開放域聲音分離。它擅長隔離音頻事件、樂器和增強語音。
AudioSep功能:
1.聲音分離能力:AudioSep的核心功能是將特定聲音與複雜的音頻環境分開,這在各種應用場景中非常有用。
2.自然語言查詢:與傳統的聲音分離模型不同,AudioSep允許用戶通過自然語言描述指定想要分離的聲音,大大提高了模型的靈活性和易用性。例如,用戶可以簡單地輸入「隔離鋼琴聲音」或「去除背景噪音」等指令。"
3.零樣本概括:AudioSep具有強大的零樣本概括能力,這意味著它可以在看不見的、未標記的數據上表現出色。例如,在智能家居環境中,可能存在各種聲音源(例如電視、空調、人聲等),能夠零樣本概括的模型可以更準確地識別和隔離這些聲音,而不必單獨訓練每個聲音。
4.開放領域應用程式:AudioSep是一個開放域聲音分離模型,這意味著它不限於處理特定類型或類別的聲音。無論是日常生活中的噪音,還是醫療保健、廣播等專業領域的特定聲音,AudioSep都有能力應對它。
項目和演示:https://audio-agi.github.io/Separate-Anything-You-Describe/
論文:https://arxiv.org/abs/2308.05037
GitHub:https://github.com/Audio-AGI/AudioSep
HuggingFace演示:https://huggingface.co/spaces/Audio-AGI/AudioSep
工作原理:
模型架構:
AudioSep由兩個關鍵組件組成:文本編碼器和聲音分離模型。文本編碼器處理自然語言查詢並將其轉換為固定長度的載體。聲音分離模型負責從混合音頻中提取目標聲音。
1.文本編碼器:該部分使用自然語言處理(NLP)技術(通常是某種形式的Transformer模型)來理解用戶的自然語言查詢。它將文本信息編碼為多維載體。
2.聲音分離模型:這部分通常是深度神經網絡,接收文本編碼器輸出的多維載體和混合音頻作為輸入,然後輸出分離後的音頻。
數據流和處理:
1.接收查詢和音頻:當用戶提出自然語言查詢和混合音頻時,兩者都將被反饋到模型中。
2.文本編碼:自然語言查詢首先由文本編碼器處理並轉換為多維載體。
3.音頻分離:將多維載體和混合音頻輸入到聲音分離模型中,模型將輸出分離後的音頻。
4.結果輸出:用戶最終將收到分離的音頻。該過程可以實時或離線進行。
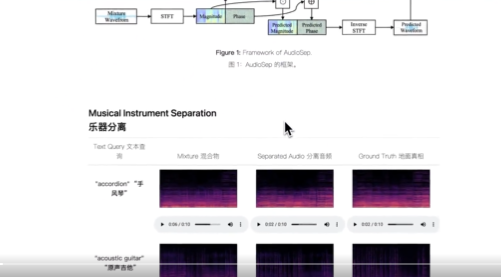
AudioSep模型在各種任務中進行了廣泛評估,包括音頻事件分離、樂器分離和語音增強。該模型展示了強大的分離性能和令人印象深刻的零樣本概括性。