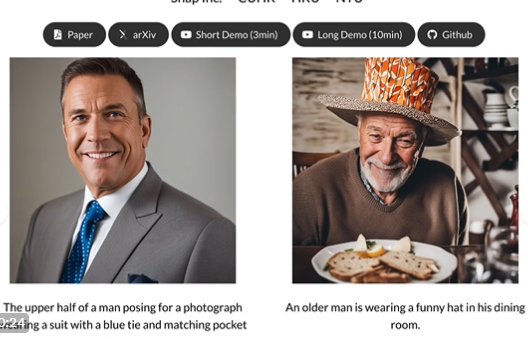
Can generate realistic portrait images.
The human image generated by this model is not only realistic, but also has a high sense of three-dimensional structure. It can understand the three-dimensional structure behind the image. It’s like you not only see a person, but also feel the way he stands, the outline of his face, etc.
HyperHuman is trained on a dataset that contains 340 million images and comprehensive annotations such as body pose, depth and surface normals.
The generated human image is not only realistic, but also has a high sense of three-dimensional structure, which has high application value in games, movie production or virtual reality. You can generate a variety of human images through simple descriptions or skeleton drawings without professional image design skills.
Main features:
HumanVerse Dataset: This is a large-scale human-centered dataset that contains 340 million images and comprehensive annotations such as human pose, depth and surface normals. This provides rich training data for the model.
Latent Structure Diffusion Model: This is a model that can simultaneously denoise depth and surface normals as well as the synthesized RGB image. This means that it not only generates images, but also understands the three-dimensional structure of images.
Structure-Guided Refiner: This is a component used to further improve image quality. It accepts the output of potential structural diffusion models and refines them to produce higher-resolution and more realistic images.
Projects and demonstrations:https://snap-research.github.io
Thesis:https://arxiv.org/abs/2310.08579
GitHub:https://github.com/snap-research/HyperHuman
Working principle:
1. Data preparation stage: First, use the human universe dataset to train the model. This dataset contains a large number of human images and associated annotations such as depth, surface normals and pose.
2. Latent structure diffusion model: At this stage, the model accepts text descriptions and posture skeletons as inputs. These inputs are processed through an encoder-decoder architecture to produce a denoised image, depth and surface normals. This step is critical because it not only generates an image, but also generates three-dimensional structural information related to the image.
3. Structure-guided refiner: This component further improves image quality. It accepts the output of a potential structural diffusion model and uses a specially designed neural network to refine it. In this way, the output image is not only higher in resolution, but also more realistic.