WikiChat is based on English Wikipedia information. When it needs to answer a question, it finds relevant and accurate information on Wikipedia first, and then provides an answer, ensuring that the answer is both useful and reliable.
In the mixed human and LLM evaluations, WikiChat achieved 97.3% factual accuracy, which is also generally higher than other models.
It produces few hallucinations and is highly conversational and has low latency.
(The online test address given by ⚠️ I tried a few times and it didn’t work, so I can’t evaluate the accuracy)
Main features:
- Highly accurate: Because it relies directly on Wikipedia, an authoritative and frequently updated source of information, WikiChat is very accurate in providing facts and figures.
- Reduce the “illusion”: LLMs are prone to misinformation when talking about the latest events or less popular topics. WikiChat reduces this information illusion by combining Wikipedia data.
- Conversational: Despite its emphasis on accuracy, WikiChat is still able to maintain a smooth and natural conversation style.
- Adaptable: It can adapt to various types of queries and conversation scenarios.
- Efficient performance: Through optimization, WikiChat can answer questions faster while reducing operating costs.
Working principle:
WikiChat uses model distillation technology to transform GPT-4-based models into smaller, more efficient LLaMA models (7 billion parameters) to improve response speed and reduce costs.
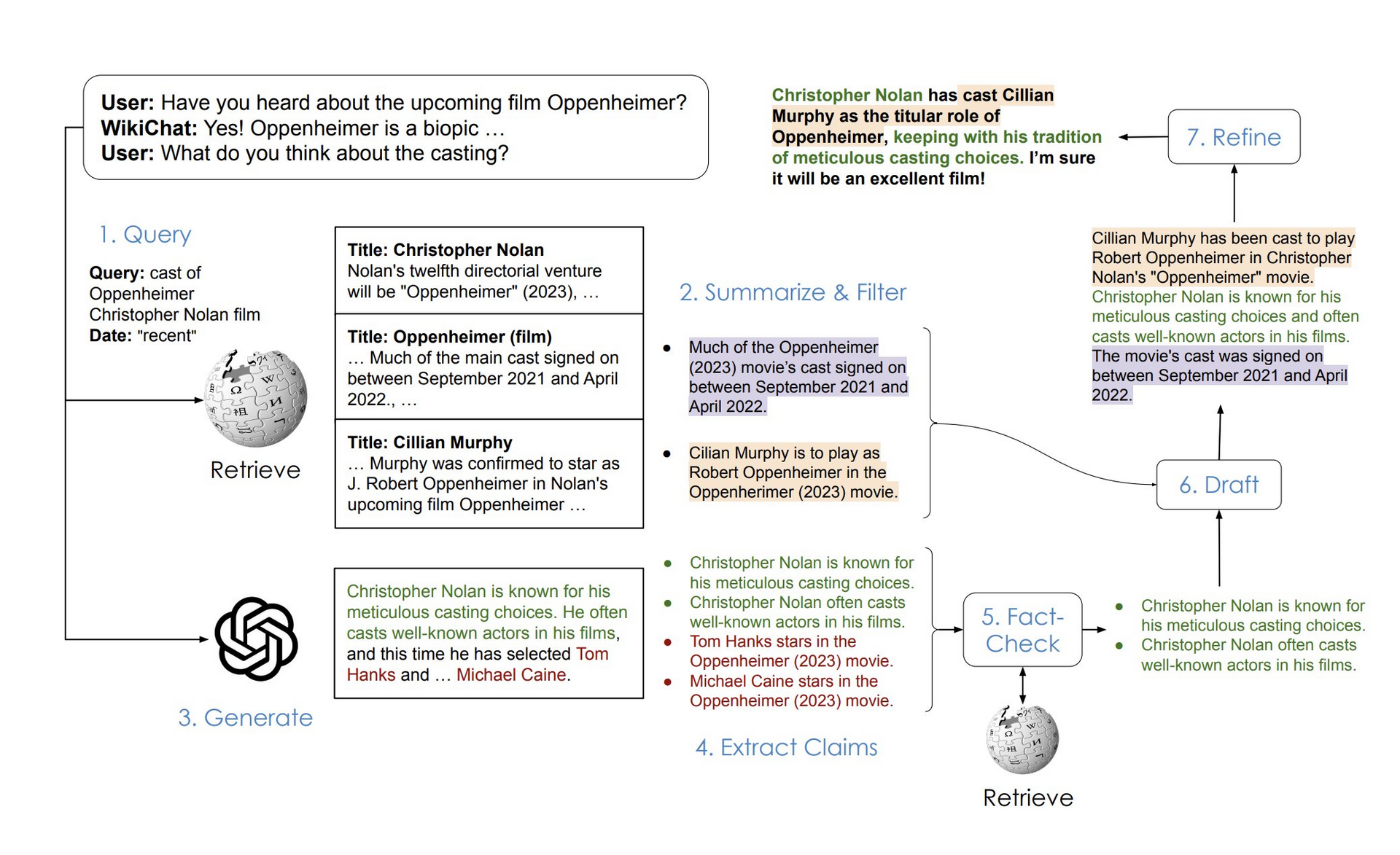
WikiChat’s workflow involves multiple stages, including retrieval, summarization, generation, fact checking, and more. Each stage is carefully designed to ensure the accuracy and fluency of the overall conversation.
1. Retrieving information: When having a conversation with a user, WikiChat first determines whether access to external information is required. For example, when a user asks a specific question or needs a more comprehensive answer. WikiChat generates a search query to capture the user’s interests and based on this query retrieves relevant information from a knowledge base such as Wikipedia.
2. Summarize and filter: The retrieved information may contain relevant and irrelevant parts. WikiChat extracts relevant parts and summarizes them into key points, while filtering out irrelevant content.
3. Generate LLM responses: Next, use a large language model such as GPT-4 to generate responses with a conversation history. The content generated by this step is often interesting and relevant, but it is inherently unreliable because it may contain unverified or incorrect information.
4. Fact-checking: WikiChat breaks down LLM’s response into multiple claims and fact-checks each claim. It uses a retrieval system to obtain evidence for each claim from the knowledge base and validates the claim based on that evidence. Only those claims that are supported by evidence are retained.
5. Form a response: Finally, WikiChat uses filtered and verified information to form an engaging response. The process is divided into two steps: first generate a draft response, and then optimize and improve it based on relevance, naturalness, non-repetition, and timing.
Performance under mixed human and large language model (LLM) assessment methods:
1. High factual accuracy: In simulated conversations, WikiChat’s best-of-breed system achieved 97.3% factual accuracy. This means that when it answers questions or provides information, almost all of its responses are based on facts and real data.
2. Comparison with GPT-4: When it comes to head knowledge (i.e., common or popular topics), tail knowledge (i.e., less common or less discussed topics), and recent knowledge (i.e., the latest happenings or information), WikiChat has improved factual accuracy by 3.9%, 38.6%, and 51.0%, respectively, compared to GPT-4. This shows that WikiChat has significantly improved when dealing with different types of information, especially when dealing with less discussed topics and the latest information.
3. Comparison to search-based chatbots: Compared to previous state-of-the-art search-based chatbots, WikiChat not only performs better in factual accuracy, but it also performs better in providing information and attracting customer engagement. This means WikiChat is able to provide a richer and more interesting conversation experience.
Overall, WikiChat’s superior performance in handling complex, dynamic, and diverse information needs, especially in terms of accuracy and customer engagement, has been significantly improved.
GitHub:https://github.com/stanford-oval/WikiChat
Paper:https://arxiv.org/abs/2305.14292
Online experience:https://wikichat.genie.stanford.edu