維基聊天基於英語維基百科信息。當它需要回答問題時,它會首先在維基百科上找到相關且準確的信息,然後提供答案,確保答案既有用又可靠。
在人類和LLM混合評估中,WikiChat的事實準確率達到了97.3%,這也普遍高於其他模型。
它幾乎不會產生幻覺,具有高度對話性,延遲時間低。
(The online test address given by ⚠️ I tried a few times and it didn't work, so I can't evaluate the accuracy)
主要特點:
- 高度準確:由於維基聊天直接依賴於維基百科(一個權威且經常更新的信息來源),因此它在提供事實和數據方面非常準確。
- 減少「幻覺」:LLM在談論最新事件或不太受歡迎的話題時容易出現錯誤信息。維基聊天通過結合維基百科數據來減少這種信息錯覺。
- 對話式:儘管維基聊天強調準確性,但仍然能夠保持流暢、自然的對話風格。
- 適應性:可以適應各種類型的查詢和對話場景。
- 高效性能:通過優化,WikiChat可以更快地回答問題,同時降低運營成本。
工作原理:
WikiChat使用模型蒸餾技術將基於GPT-4的模型轉換為更小、更高效的LLaMA模型(70億個參數),以提高響應速度並降低成本。
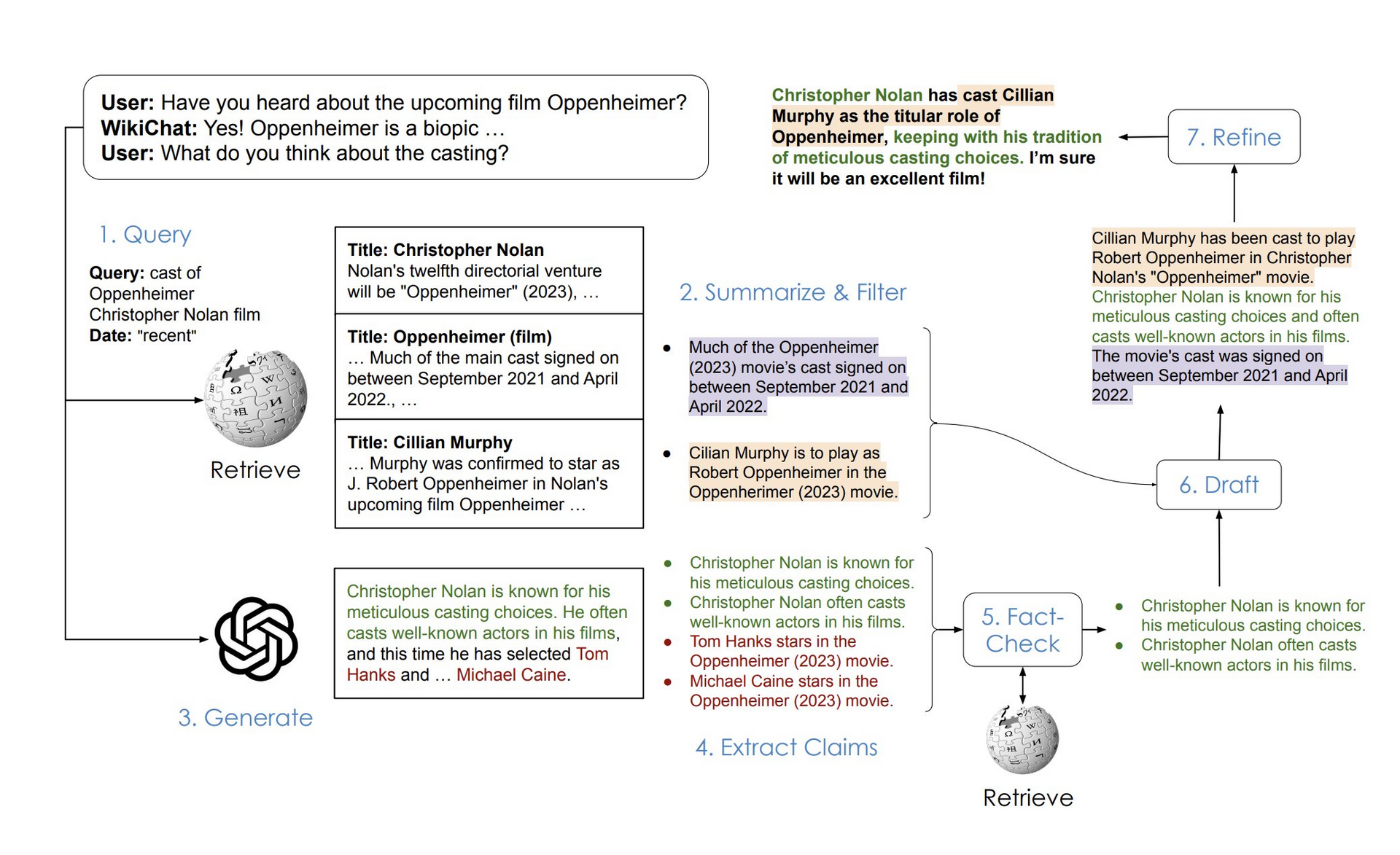
WikiChat的工作流程涉及多個階段,包括檢索、總結、生成、事實檢查等。每個階段都經過精心設計,以確保整個對話的準確性和流暢性。
1.檢索信息:與用戶對話時,維基聊天首先確定是否需要訪問外部信息。例如,當用戶提出特定問題或需要更全面的答案時。WikiChat生成搜索查詢以捕獲用戶的興趣,並基於此查詢從維基百科等知識庫檢索相關信息。
2.總結和過濾:檢索到的信息可能包含相關部分和不相關部分。WikiChat提取相關部分並將其總結為關鍵點,同時過濾掉不相關的內容。
3.生成LLM響應:接下來,使用GPT-4等大型語言模型來生成具有對話歷史記錄的響應。此步驟生成的內容通常很有趣且相關,但它本質上是不可靠的,因為它可能包含未經驗證或不正確的信息。
4.事實核查:WikiChat將LLM的回應分解為多個主張,並對每個主張進行事實核查。它使用檢索系統從知識庫中獲取每個主張的證據,並基於該證據驗證主張。僅保留那些有證據支持的主張。
5.形成回應:最後,維基聊天室使用經過過濾和驗證的信息來形成引人入勝的回應。該過程分為兩個步驟:首先生成回復草稿,然後根據相關性、自然性、非重複性和時機進行優化和改進。
混合人類和大型語言模型(LLM)評估方法下的性能:
1.高事實準確性:在模擬對話中,WikiChat的同類最佳系統實現了97.3%的事實準確性。這意味著當它回答問題或提供信息時,幾乎所有的回答都是基於事實和真實數據。
2.與GPT-4的比較:當談到頭部知識時(即,常見或流行話題)、尾部知識(即,不太常見或討論較少的主題),以及最近的知識(即,最新事件或信息),與GPT-4相比,WikiChat的事實準確性分別提高了3.9%、38.6%和51.0%。這表明維基聊天在處理不同類型的信息時有了顯著的改進,尤其是在處理討論較少的主題和最新信息時。
3.與基於搜索的聊天機器人的比較:與之前最先進的基於搜索的聊天機器人相比,WikiChat不僅在事實準確性方面表現更好,而且在提供信息和吸引客戶參與方面也表現更好。這意味著維基聊天能夠提供更豐富、更有趣的對話體驗。
總體而言,WikiChat在處理複雜、動態和多樣化的信息需求方面的卓越性能,特別是在準確性和客戶參與度方面,得到了顯著提高。
GitHub:https://github.com/stanford-oval/WikiChat
紙張:https://arxiv.org/abs/2305.14292
在線體驗:https://wikichat.genie.stanford.edu