GPT 4 is the lowest on Google
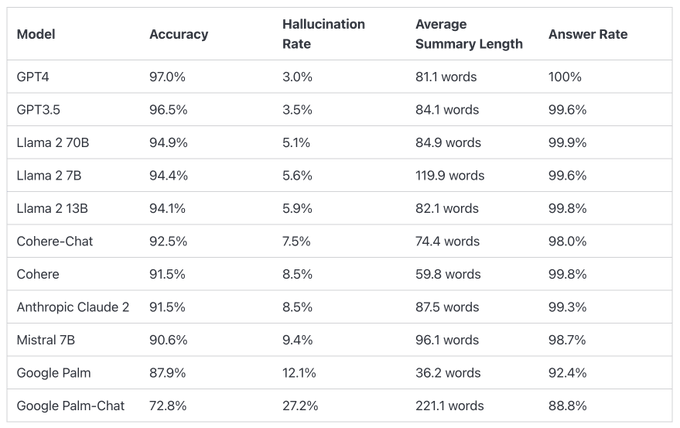
The list compares the hallucination performance of different large language models when summarizing short documents.
GPT-4 has an accuracy rate of 97.0%, a hallucination rate of 3.0%, and a response rate of 100.0%.
Google Palm is at the bottom of the pack, with Palm Chat 2 having an accuracy rate of 72.8%, a hallucination rate of 27.2%, and a response rate of 88.8%.
This leaderboard is calculated by @vectara’s hallucination evaluation model, which assesses how often LLMs introduce hallucinations when summarizing documents. The data of the leaderboard is regularly updated as the model and LLM are updated.
The data on the leaderboard includes accuracy, hallucination rates, response rates, and average summary length (word count) for different models. For example, GPT-4 has an accuracy rate of 97.0%, a hallucination rate of 3.0%, a response rate of 100.0%, and an average summary length of 81.1 words. Other models such as GPT-3.5, Llama 2 70B, and Llama 2 7B also have similar data.
To determine this leaderboard, Vetera trained a model to detect hallucinations in LLM outputs, using various open-source datasets from fact-consistency studies on summarized models. They then provided 1000 short documents to the said LLM via a public API and asked them to summarize each document, using only the facts presented in the document. Of these 1,000 documents, only 831 documents were summarized by each model, and the rest were rejected by at least one model due to content limitations. Using these 831 documents, they calculated the overall accuracy (no hallucinations) and hallucination rates (100 – accuracy) for each model.
The model is open source for commercial use on Hugging Face at https://huggingface.co/vectara/hallucination_evaluation_model
GitHub:https://github.com/vectara/hallucination-leaderboard