GPT 4是Google上最低的
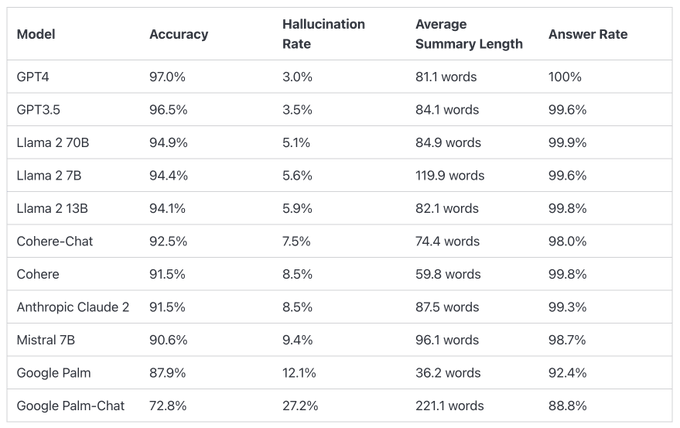
該列表比較了不同大型語言模型在總結短文檔時的幻覺性能。
GPT-4的準確率為97.0%,幻覺率為3.0%,反應率為100.0%。
Google Palm墊底,Palm Chat 2的準確率為72.8%,幻覺率為27.2%,響應率為88.8%。
該排行榜由@vectara的幻覺評估模型計算,該模型評估LLM在總結文檔時引入幻覺的頻率。隨著模型和LLM的更新,排行榜的數據會定期更新。
排行榜上的數據包括不同模型的準確性、幻覺率、響應率和平均摘要長度(字數)。例如,GPT-4的準確率為97.0%,幻覺率為3.0%,響應率為100.0%,平均摘要長度為81.1個單詞。GPT-3.5、Llama 2 70 B和Llama 2 7 B等其他型號也有類似的數據。
為了確定這個排行榜,Vetera使用來自總結模型的事實一致性研究的各種開源數據集訓練了一個模型來檢測LLM輸出中的幻覺。然後,他們通過公共API向LLM提供了1000份簡短文檔,並要求他們僅使用文檔中提供的事實來總結每個文檔。在這1,000份文檔中,每個模型只總結了831份文檔,其餘的文檔由於內容限制被至少一個模型拒絕。使用這831份文件,他們計算了每個模型的總體準確性(無幻覺)和幻覺率(準確性100)。
該模型在Hugging Face上開源供商業用途, https://huggingface.co/vectara/hallucination_evaluation_model
GitHub:https://github.com/vectara/hallucination-leaderboard