以下內容由原文翻譯而來
在本文中,我們居間了第一個名為SEARCH 2Sign的多語言手語數據集,該數據集基於公共手語數據,其中包括美國手語(ADL)和其他七種語言。
該數據集將大量視頻轉換為簡化、模型友好的格式,並針對訓練seq 2 seq和text2 text等翻譯模型進行了優化。基於這個新數據集,提出了SignLLM,這是第一個多語言手語生成(SLP)模型,其中包括兩種新穎的多語言SLP模式,允許根據輸入文本或提示生成手語手勢。
這兩個模型都可以使用新的基於損失和強化學習的模塊,通過增強模型自主採樣高質量數據的能力來加速訓練。演示了SignLLM的基準結果,這表明我們的模型在八種手語的SLP任務上實現了最先進的性能。
數據集和主要方法
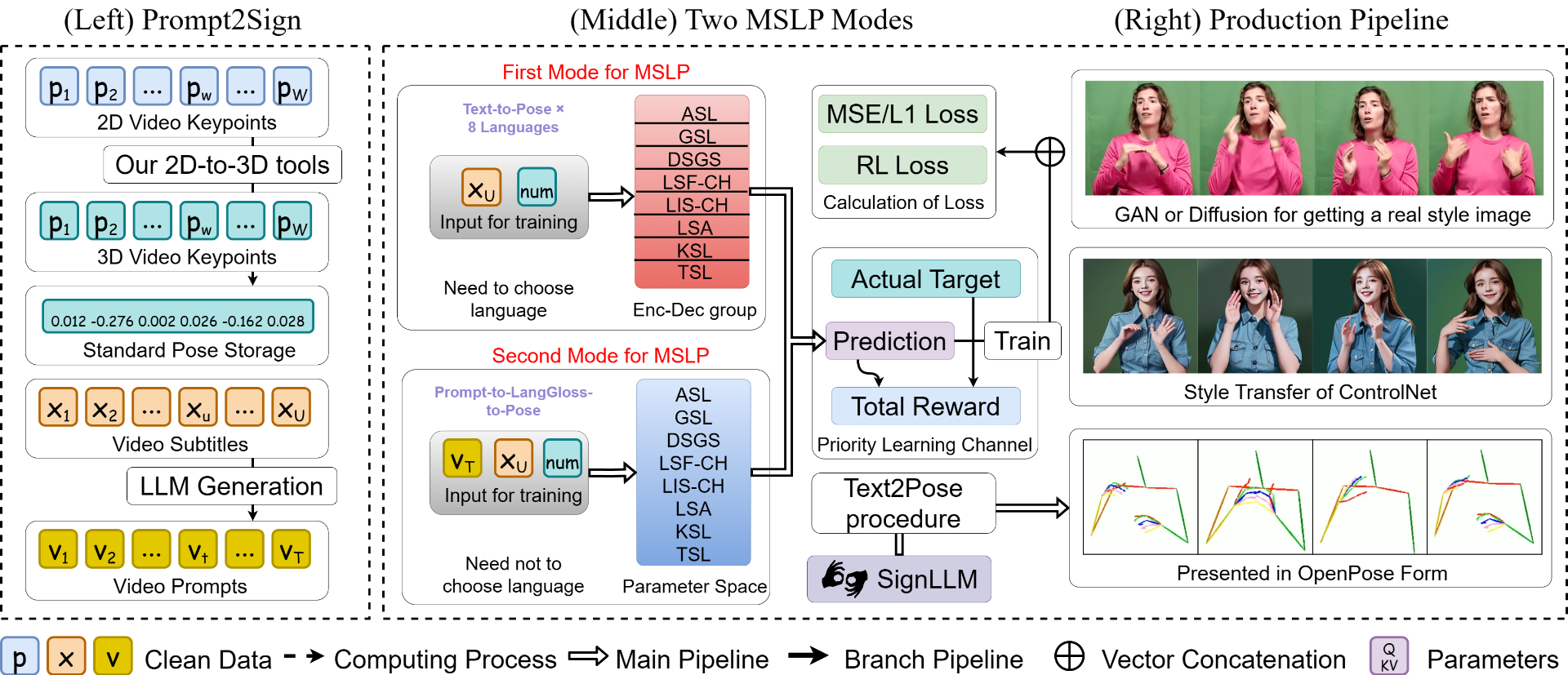
(左)PROMPT 2SIGN數據集的結構和形式概述。(C)文本2LangGloss與MLSF之間的交互原理,以及強化學習的計算方法。(右圖)SIGNLLM的輸出可以轉換為大多數姿勢表示格式,然後可以通過風格轉移/特別微調的生成模型將其渲染為真實的人類外觀。
其他方法
在工作中,通過合併一個單一標籤來改進文本2Gloss框架,該標籤生成具有必要語言屬性的Gloss,同時還通過神經網絡中的變量V和Xu表示深刻的特徵。
此外,還居間了五個關鍵要素--用戶、代理、環境、疊代更新過程和PLC--它們共同概述了針對序列預測量身定製的強化學習過程。
如果您想了解更多信息,可以單擊視頻下方的連結。
感謝您觀看此視頻。如果您喜歡,請訂閱並點讚。謝謝
原文:https://signllm.github.io/
紙張:https://arxiv.org/abs/2405.10718
輸油管: