他們聲稱比GPT-4更好。所以魯本做了4個測試:
原作者:@RubenHssd
測試#1-初始化網站的UI
測試#2-撰寫LinkedIn帖子
測試#3-測試他們的PDF Vision
測試#4→大型營銷技巧
測試1:初始化UI
測試2:撰寫LinkedIn帖子
這篇文章是關於區塊鏈+版稅的未來。
克勞德3:
有趣的任務。
比平時更長。
沒有標題格式。
GPT-4:
我真的很討厭他們的表情符號。
太長了,太瘋狂了。
感覺我的主題更完整了。
測試3:測試他們的PDF功能
這實際上是一個平局。
PDF技術含量很高,包含可以從圖像中檢索的設計、圖表和文本。
但如果我必須向某人頒發獎牌,那仍然是ChatGPT,因為它稍微詳細一些。
僅此而已,原作者:@RubenHssd
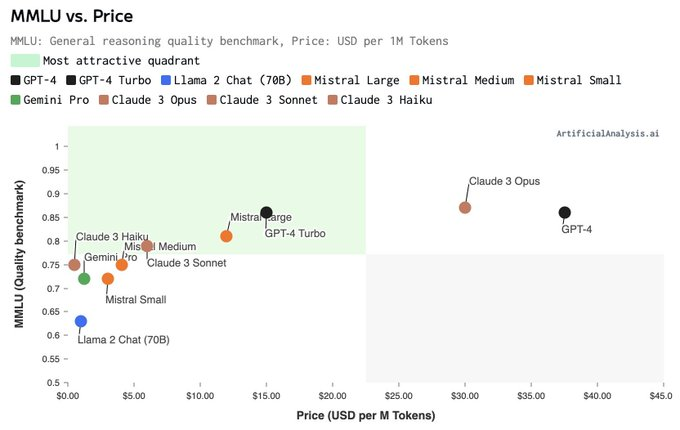
Anthropic太棒了。Claude-3發布了兩件事:
-
領域專家的基準。我對飽和的MMLU和HumanEval不太感興趣。克勞德專門選擇了金融、醫學和哲學作為專家領域,並報告了表現。我建議所有LLM模型卡都遵循這一點,以便不同的下游應用程式知道會發生什麼。
-
拒絕率分析。法學碩士對無辜問題過于謹慎的回答正在成為一種流行病。Anthropic通常處於極端安全狀態,但他們認識到了這個問題並強調了他們在這方面的努力。太好了!
新視頻: