如何使用能力較差的人工智慧模型來引導和控制更強大的人工智慧模型。
這項研究的目的是解決這樣一個問題:未來,當人工智慧變得比人類更聰明時,人類如何有效地控制這些人工智慧。
結果表明,即使是相對較弱的人工智慧模型,也可以在一定程度上有效引導和影響更先進的人工智慧模型的訓練和行為。例如,使用早期人工智慧模型GPT-2來幫助訓練更先進的人工智慧模型GPT-4。
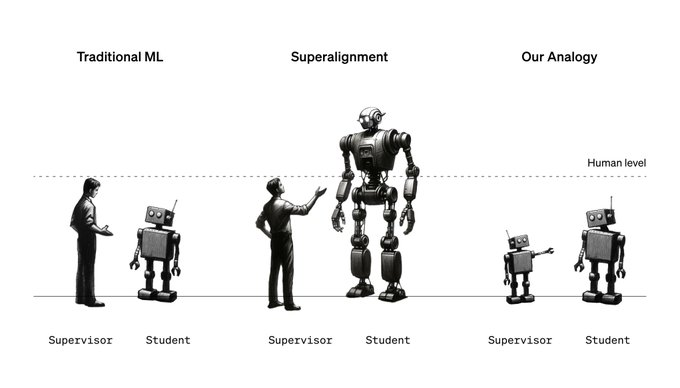
1.從弱到強的概括概念:本研究探討了「從弱到強的概括」的概念,即使用較弱的人工智慧模型來監督和引導較強的人工智慧模型。
這裡,「弱」和「強」指的是模型的能力或複雜性。較弱的模型通常是早期開發的模型,功能有限,而較強的模型則更加先進和複雜。
2.實驗設置:在這項研究中,OpenAI使用GPT-2作為一個較弱的模型來監督GPT-4的訓練。GPT-2是一個早期的AI語言模型,而GPT-4是一個更先進、更大、更複雜的模型。
通過這種設置,研究人員希望了解較弱的模型是否可以有效影響較強模型的學習和行為。
研究人員使用GPT-2的輸出將任務傳達給GPT-4。
3.研究結果:實驗結果表明,該方法使GPT-4達到了GPT-3和GPT-4之間的性能水平。這表明GPT-2能夠在一定程度上引導GPT-4學習特定的任務或行為。即使GPT-2的功能遠不及GPT-4,GPT-4也可以達到接近其全部潛力的性能水平。
這意味著,當擔任主管時,較弱的人工智慧模型(例如GPT-2)也會對更強大的人工智慧模型(例如GPT-4)產生重大影響。
4.研究意義:
這一發現對人工智慧的對齊和控制具有影響:
- 監管薄弱的有效性:通常,我們認為人工智慧模型的監管者需要比監督模型更強大或至少同等強大,才能確保有效的學習和控制。然而,這項研究表明,即使能力較差的模型也可以有效地指導更強大的模型。
- 對未來人工智慧對齊的影響:隨著人工智慧技術的發展,未來可能會出現遠遠超出人類智能範圍的人工智慧系統。在這種情況下,人類將是相對較弱的監督者。這項研究提供了一個可能的解決方案,即使是薄弱的監管者也可以有效地引導和控制超級智能人工智慧。
- 超人智能的安全管理:這項研究為如何安全管理和控制超人智能人工智慧提供了新思路。它表明,通過正確的方法和技術,即使人類成為軟弱的監督者,我們也可以期望保持對先進人工智慧系統的有效控制。
為了啟動該領域的更多研究,OpenAI發布了開原始碼和論文。
GitHub:https://github.com/openai/weak-to-strong
紙張: https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
OpenAI還啟動了一項1000萬美金的贈款計劃,以支持關於超人類AI對齊的廣泛研究,特別是與弱到強泛化相關的研究。應用: https://openai.com/blog/superalignment-fast-grants