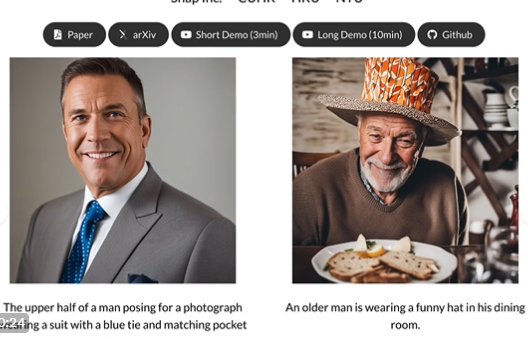
可以生成逼真的肖像圖像。
該模型生成的人體圖像不僅逼真,而且具有高度的三維結構感。它可以理解圖像背後的三維結構。就好像你不僅看到一個人,還能感覺到他的站立方式、他的臉輪廓等。
HyperHuman在包含3.4億張圖像和身體姿勢、深度和表面法向等全面注釋的數據集上進行訓練。
生成的人體圖像不僅逼真,而且具有高度的三維結構感,在遊戲、電影製作或虛擬實境中具有很高的應用價值。無需專業的圖像設計技能,即可通過簡單的描述或骨架圖生成各種人體圖像。
主要特點:
HumanVerse數據集:這是一個以人為本的大規模數據集,包含3.4億張圖像和人體姿勢、深度和表面法向等全面注釋。這為模型提供了豐富的訓練數據。
潛在結構擴散模型:這是一個可以同時對深度和表面法向以及合成的GB圖像進行去噪的模型。這意味著它不僅生成圖像,而且還理解圖像的三維結構。
結構引導細化器:這是一個用於進一步提高圖像質量的組件。它接受潛在結構擴散模型的輸出並對其進行細化以產生更高解析度和更真實的圖像。
項目和演示:https://snap-research.github.io
論文:https://arxiv.org/abs/2310.08579
GitHub:https://github.com/snap-research/HyperHuman
工作原理:
1.數據準備階段:首先,使用人類宇宙數據集來訓練模型。該數據集包含大量人類圖像和相關注釋,例如深度、表面法向和姿勢。
2.潛在結構擴散模型:在此階段,模型接受文本描述和姿勢骨架作為輸入。這些輸入通過編碼器-解碼器架構進行處理,以產生降噪圖像、深度和表面法向。這一步至關重要,因為它不僅生成圖像,而且還生成與圖像相關的三維結構信息。
3.結構引導細化器:該組件進一步提高圖像質量。它接受潛在結構擴散模型的輸出,並使用專門設計的神經網絡對其進行細化。這樣,輸出圖像不僅解析度更高,而且更真實。