大型語言模型可以具有視覺和繪圖功能。
該項目由騰訊的AILab-CVC團隊開發。SEED的主要功能是將圖像轉換為一系列離散的視覺代碼。它就像一個「翻譯器」,可以將圖片「翻譯」成特殊的「語言」(視覺代碼),以便機器人能夠理解和處理它。
這些代碼具有一維因果依賴關係和高級語義(SEED將圖像信息轉換為相互之間存在因果關係的代碼序列,例如單詞或文本中的單詞),使它們能夠在與文本相同的模型中進行處理。
項目:https://github.com/AILab-CVC/SEED
論文:https://arxiv.org/abs/2310.01218
演示:即將推出.
[How它有效嗎?]
1.視覺代碼生成:首先,SEED將您提供的圖像轉換為特殊的代碼串(視覺代碼)。這些代碼包含有關圖片的所有重要信息,例如顏色、形狀和對象。
2.與文本對齊:這些視覺代碼按照一定的順序排列,就像句子中的單詞一樣。通過這種方式,機器人可以像處理文本一樣處理代碼。
3.高級理解:更重要的是,這些視覺代碼還包含圖片的「含義」。例如,如果圖片中有一隻狗在跑,那麼這些代碼可以表達「狗」和「跑」的概念。
4.多模式任務:一旦機器人通過SEED理解了這些視覺代碼,它就可以做許多以前無法做的事情,例如描述圖片、回答有關圖片的問題,甚至根據您的描述生成新圖片。
例子:
假設您有一張黃色小狗在草地上玩球的照片。你問機器人:「這是什麼圖片?"
無種子:機器人會說:「抱歉,我看不懂圖片。"
有SEED:SEED將圖像轉換為視覺代碼,然後機器人說:「這是一隻黃色小狗在草地上玩球。"
通過SEED,機器人不僅可以理解文本,還可以理解和生成圖像,使它們變得更加強大和多才多藝。
[集成到大型語言模型]
將SEED與大型語言模型集成可以實現多模式處理能力。這樣的模型不僅可以處理純文本任務,還可以處理圖像字幕、圖像/視頻問答和文本到圖像生成等多模式任務。
SEED-LLaMA:
SEED-LLaMA是一個預訓練的大型語言模型(LLM),集成了SEED標記。該模型在多模式數據上預訓練,並通過指令進行調整(微調)。
特點和性能:
能夠處理多項任務,例如圖像字幕、圖像/視頻問答和文本到圖像生成。
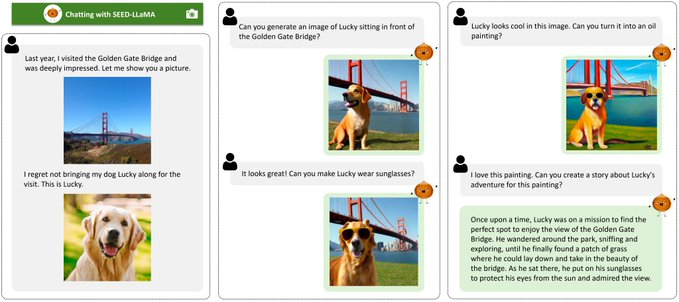
展示多模式生成在多輪環境中的綜合出現能力。
這意味著SEED不僅可以單獨處理圖像或文本,還可以在多輪對話中將兩者結合起來以生成新內容。例如,它可以根據文本描述生成圖像,然後根據新的文本輸入修改圖像。
例子:
假設您首先描述一個「紅蘋果」,SEED生成一個紅蘋果的圖像。然後你說「添加一片綠葉」,SEED就可以在原始的紅蘋果圖像中添加一片綠葉。
實驗結果:
SEED-LLaMA擅長多種多模式任務,包括圖像字幕、圖像/視頻問答和文本到圖像生成。