Large language models can be given visual and drawing capabilities.
The project was developed by Tencent’s AILab-CVC team. The main function of SEED is to convert images into a series of discrete visual codes. It is like a “translator” that can “translate” pictures into a special “language”(visual code) so that the robot can understand and process it.
These codes have 1D causal dependencies and high-level semantics (SEED converts image information into a sequence of codes that have causal relationships between them, like words or words in text), Enabling them to be processed in the same model as text.
Project:https://github.com/AILab-CVC/SEED
Thesis:https://arxiv.org/abs/2310.01218
Demonstration: Coming soon…
[How does it work?]
1. Visual code generation: First, SEED converts the image you give it into a special string of code (visual code). These codes contain all important information about the picture, such as colors, shapes and objects.
2. Align with text: These visual codes are arranged in a certain order, just like words in a sentence. In this way, the robot can process the code like text.
3. Advanced understanding: What’s more important is that these visual codes also contain the “meaning” of the picture. For example, if there is a dog running in the picture, then these codes can express the concepts of “dog” and “running”.
4. Multimodal tasks: Once the robot understands these visual codes through SEED, it can do many things it couldn’t do before, such as describing pictures, answering questions about pictures, and even generating new pictures based on your description.
Examples:
Suppose you have a picture of a yellow puppy playing with a ball on the grass. You ask the robot,”What is this picture?”
No SEED: The robot will say,”Sorry, I can’t read the pictures.”
There is SEED: SEED converts the image into visual code, and then the robot says,”This is a yellow puppy playing with a ball on the grass.”
Through SEED, robots can not only understand text, but also understand and generate images, making them more powerful and versatile.
[Integrated into large language models]
Integrating SEED with the large language model can achieve multimodal processing capabilities. Such a model can handle not only pure text tasks, but also multimodal tasks such as image captioning, image/video question answering, and text-to-image generation.
SEED-LLaMA:
SEED-LLaMA is a pre-trained large language model (LLM) that integrates the SEED marker. The model is pre-trained on multimodal data and tuned (fine-tuned) through instructions.
Features and performance:
Ability to handle multiple tasks such as image captioning, image/video question answering, and text-to-image generation.
Demonstrate the combined emergence capabilities of multimodal generation in multiple rounds of contexts.
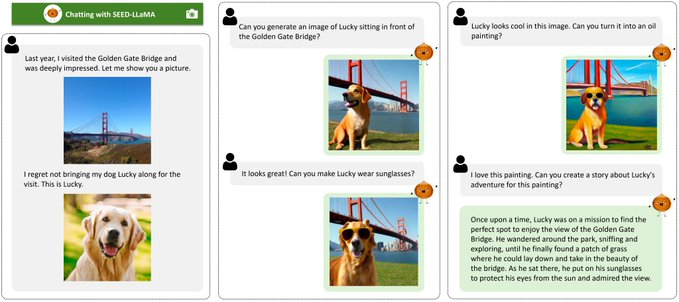
This means that SEED can not only process images or text separately, but also combine the two in multiple rounds of conversations to generate new content. For example, it can generate an image based on a text description and then modify the image based on new text input.
Examples:
Suppose you first describe a “red apple” and SEED generates an image of a red apple. Then you say,”Add a green leaf,” and SEED can add a green leaf to the original red apple image.
Experimental results:
SEED-LLaMA excels in multiple multimodal tasks, including image captioning, image/video question answering, and text-to-image generation.