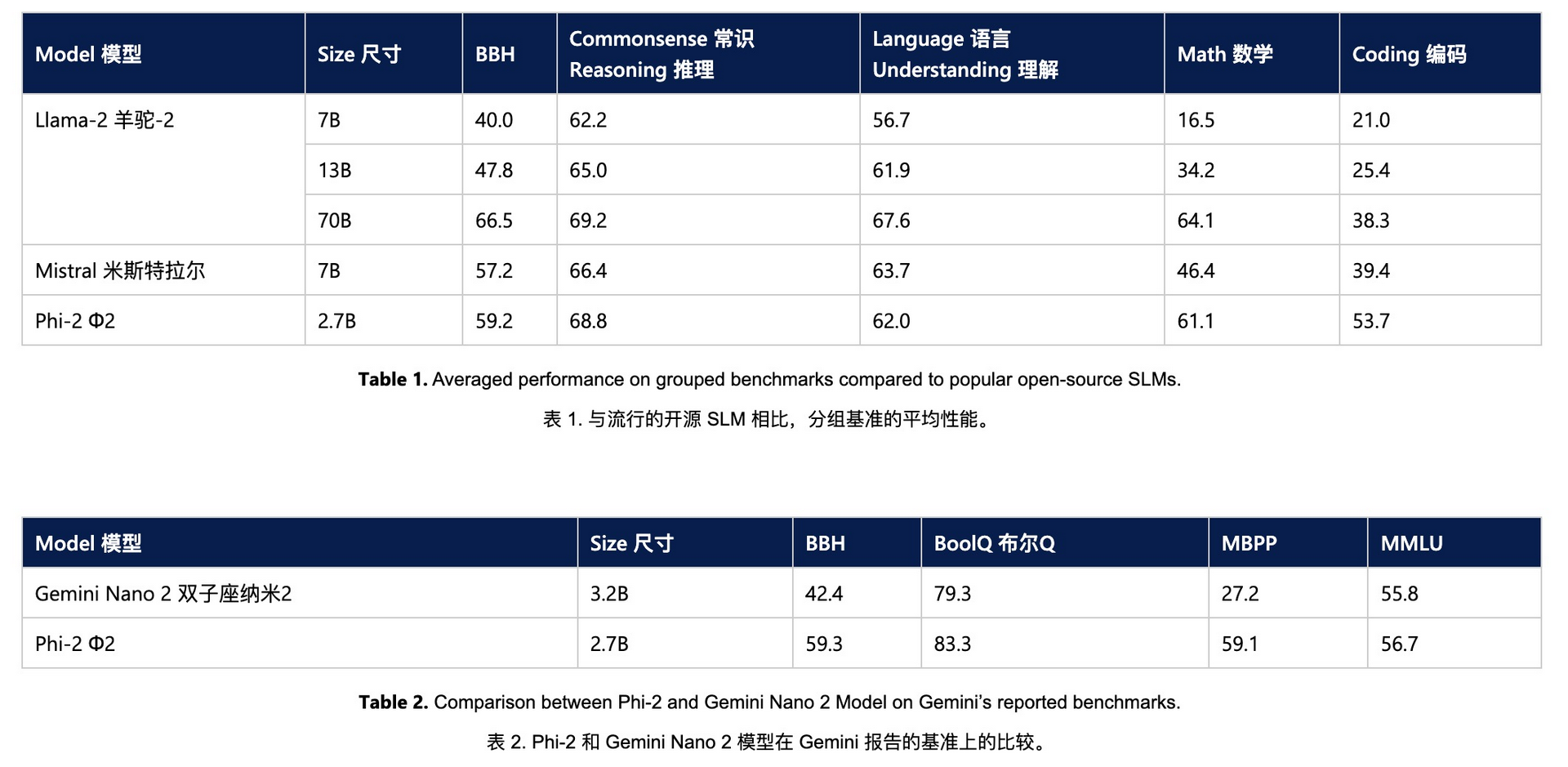
- Phi-2 has only 2.7B parameters
- Phi-2 surpasses the Mistral and Llama-2 models, which have 7B and 13B parameters, respectively
- It even surpasses the Llama-2-70B model, which has 25 times the number of parameters in multi-step inference tasks
- Microsoft says Phi-2’s excellent performance is due to the very high quality of its training data, and they have a “textbook-quality” dataset
“Textbook-Quality” Datasets: To train Phi-2, the research team created specific datasets specifically designed to teach the model to common sense reasoning and general understanding. These synthetic datasets may contain various scenarios and problems, aiming to improve the model’s accuracy and reliability in dealing with real-world problems.
Knowledge transfer: In addition, the research team successfully transferred the learned knowledge and patterns from the smaller Phi-1.5 model to the larger Phi-2 model. This not only improves the learning efficiency of Phi-2 but also accelerates its training process, allowing it to reach high levels of performance faster.
Details: https://microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/