Apple released a multimodal large language model called Ferret on December 14, which can not only accurately recognize images and describe their content.
It also recognizes and locates elements in the image, and no matter how you describe it, Ferret can accurately find and identify it in the image.
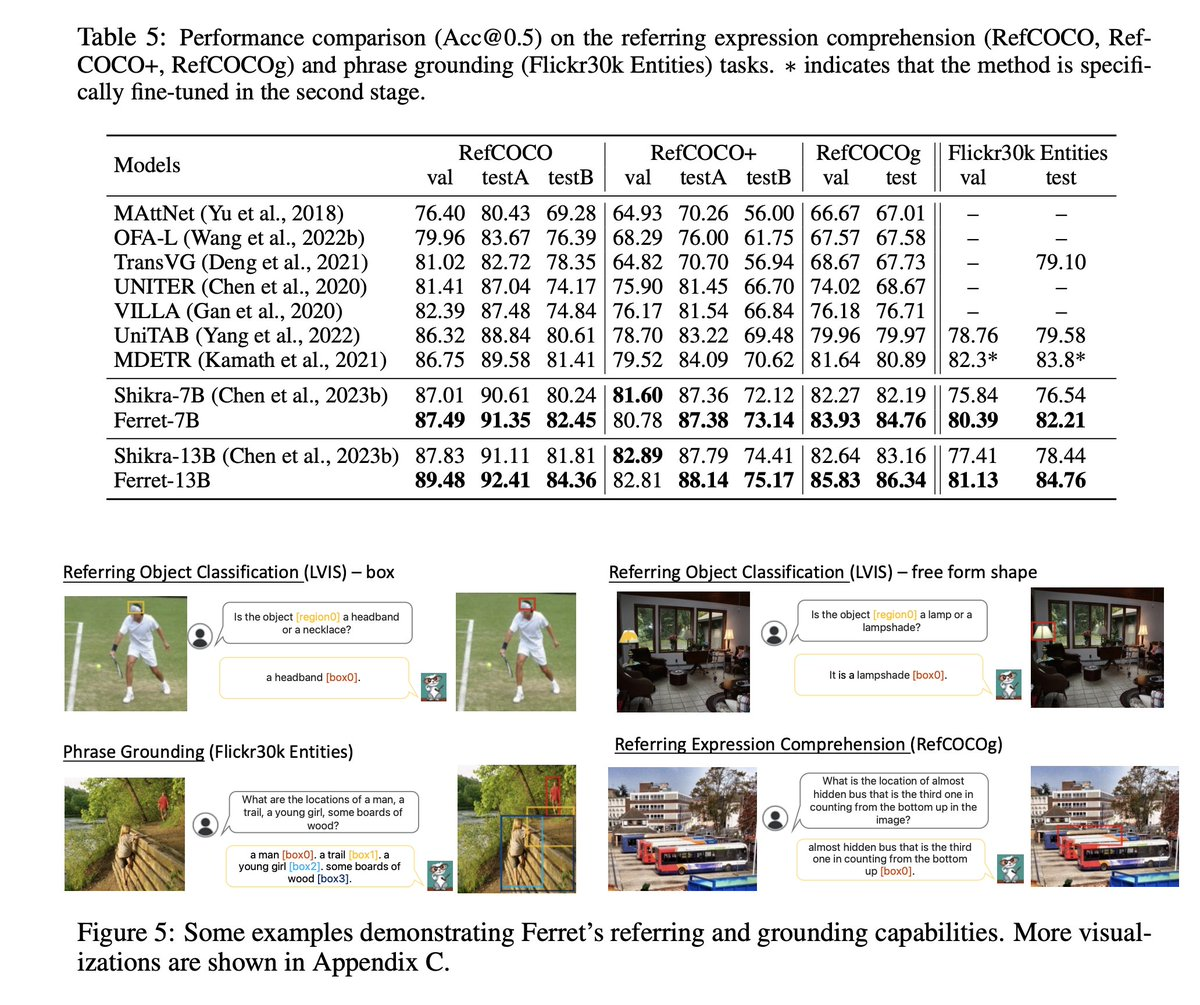

Ferret has two versions (7B, 13B), and in order to enhance the capabilities of Ferret’s model, Apple has collected a GRIT dataset. It contains 1.1M samples that contain rich hierarchical spatial knowledge.
Key functions and features:
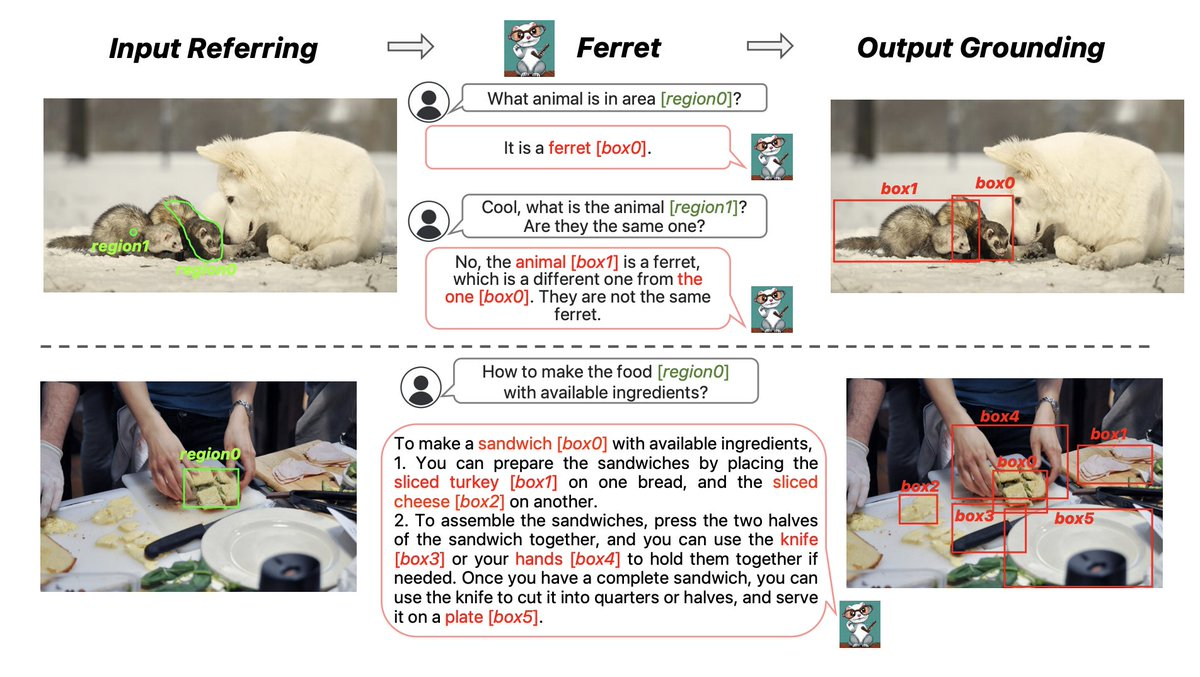
Ferret is able to understand and process the complex relationships between images and text. What makes this model special is its ability to identify and locate various elements in an image, regardless of their shape or size.
For example, referencing a specific part of an image in a conversation or finding a specific object in an image based on a text description.
Ferret is like an intelligent system that can understand pictures and words and connect them. No matter which part of the image you mention in the text or how you describe it, Ferret will accurately find and identify it in the image.
1. Multimodal Understanding: Ferret is capable of processing and understanding both images (visual information) and text (verbal information), which allows it to make connections between many different modes.
2. Spatial Reference Understanding: It is able to identify and understand the meaning of specific areas in an image, even if these areas vary in shape and size. For example, if the text mentions a specific part of an image, Ferret can recognize what that part refers to.
3. Understanding Complex Textual Descriptions: Ferret is capable of understanding various types of text descriptions, whether they are concrete or abstract. For example, “a puppy next to a red vehicle in the image” or “a smiley face in the upper right corner of the image”.
4. Open vocabulary description precise positioning: Based on these text descriptions, Ferret can accurately find and mark the corresponding objects or areas in the provided images. For example, it can identify and point out the exact location of a “puppy” or “smiley face” in an image. No matter how users describe what they want to find in the image, Ferret understands and responds.
5. Mixed Area Representation: Ferret uses an innovative representation method to process areas in images. This representation combines discrete coordinates, such as the position of a point or bounding box, with continuous features (such as the visual content of an area). This allows the model to understand and process areas of various shapes and sizes, improving the spatial understanding of images.
6. Spatial Aware Visual Sampler: To handle areas of different shapes, Ferret introduces a spatially aware visual sampler. This sampler is capable of extracting visual features based on the shape and sparsity of the region, allowing the model to handle areas of various shapes, from simple points to complex polygons.
7. Diverse Area Input: Ferret has the ability to recognize and understand various types of regions in images.
It can handle the following types of zone inputs:
Points: Ferret is able to identify specific points in an image, such as a specific location specified by the user.
Bounding Boxes: It can identify and understand bounding boxes in images, which are often used to mark objects or specific areas in an image.
Freeforms: Ferret can also handle more complex freeforms such as hand-drawn outlines, irregular shapes, or arbitrary polygons. This capability allows for more precise identification and understanding of complex areas in images.
This ability to handle diverse regional inputs makes Ferret highly flexible and powerful in image understanding, adapting to various application scenarios and user needs. Whether users provide simple dot markers, regular bounding boxes, or complex free-form shapes, Ferret can accurately identify and process them.
8. GRIT dataset: The GRIT dataset is specifically collected to train and enhance Ferret, containing 1.1M samples.
This dataset contains a wealth of hierarchical spatial knowledge, meaning it covers everything from simple objects to complex spatial relationships. Contains 95K hard-to-carry samples, which are specially designed challenging samples to improve the robustness and accuracy of the model in difficult situations.
Main manifestations:
1. Ferret-Bench evaluation: Ferret-Bench is a series of new tasks introduced to evaluate Ferret, including referential description, referential reasoning, and positioning in conversation. On these tasks, Ferret improved by an average of 20.4% compared to the best available multimodal large language models (MLLMs). This result indicates that Ferret has a significant advantage in handling more complex tasks that are closer to real-world applications.
2. Improve object illusions: Ferret can reduce errors or fictional content when describing image details, which is particularly important in the field of automated image description and analysis.
It alleviates the problem of object hallucinations, which reduce misreferences to non-existent objects when generating text descriptions, improving the accuracy and reliability of descriptions.
3. Ferret not only excels in traditional referencing and localization tasks, but also can more accurately understand and process spatial information and semantics in images. And it also excels in tasks that require referencing/positioning, semantics, knowledge, and reasoning.
Ferret is able to describe image details more accurately, reducing the illusion of non-existent objects when generating text. Through its innovative methods and technologies, it provides new possibilities for multimodal language models in spatial understanding and localization, especially when dealing with complex image and text interactions.
Suitable for a wide range of applications:
Due to its powerful image and text processing capabilities, Ferret is suitable for a wide range of applications, including image search, automatic image annotation, interactive media exploration, and more.
GitHub:https://github.com/apple/ml-ferret
Thesis: https://arxiv.org/abs/2310.07704