WayveScenes101:一个用于自动驾驶应用的高分辨率图像数据集
WayveScenes101,这是一个数据集,旨在帮助社区推进新颖视图合成的最新技术,该数据集专注于具有挑战性的驾驶场景,其中包含许多具有不断变化的几何和纹理的动态和可变形元素。
该数据集包含 101 个驾驶场景,涵盖各种环境条件和驾驶场景。该数据集专为野外驾驶场景的基准重建而设计,场景重建方法面临许多固有的挑战,包括图像眩光、快速曝光变化以及具有明显遮挡的高动态场景。
WayveScenes101,这是一个数据集,旨在帮助社区推进新颖视图合成的最新技术,该数据集专注于具有挑战性的驾驶场景,其中包含许多具有不断变化的几何和纹理的动态和可变形元素。
该数据集包含 101 个驾驶场景,涵盖各种环境条件和驾驶场景。该数据集专为野外驾驶场景的基准重建而设计,场景重建方法面临许多固有的挑战,包括图像眩光、快速曝光变化以及具有明显遮挡的高动态场景。
StockBot 是一款基于 ai 的聊天机器人,它利用 Groq 上的 Llama3 70b、Vercel 的 AI SDK 和 TradingView 的实时小部件,通过专门针对您的请求定制的实时交互式图表和界面进行对话响应。 StockBot由Groq 提供支持,闪电般快速的AI聊天机器人,可实时响应交互式股票图表、财务、新闻等。
它不仅能够展示每日市场表现热图、股票财务数据、价格历史和烛台图表,还能提供头条新闻和股票筛选器。它不仅支持股票,还涵盖了外汇、债券和加密货币,提供全面的市场分析。
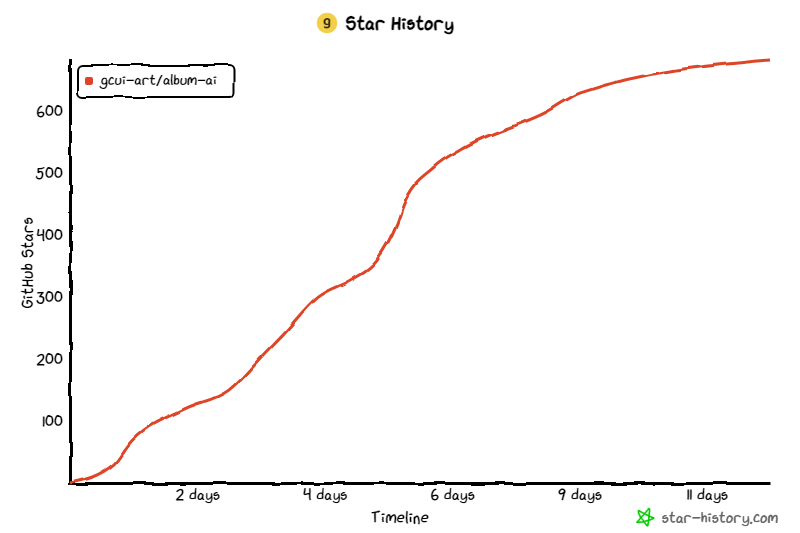
相册AI是一个实验项目,使用最近发布的gpt-4o-mini作为视觉模型,自动识别相册中图像文件的元数据。然后,它利用 RAG 技术来实现与专辑的对话。
它可以用作传统相册,也可以用作图像知识库来辅助LLM进行内容生成。
AudioNotes 是一个基于 FunASR 和 Qwen2 构建的音视频内容转结构化笔记系统。它的主要功能是快速提取音视频的内容,并通过调用大模型进行整理,将这些内容转换为结构化的Markdown笔记,便于用户快速阅读和理解。
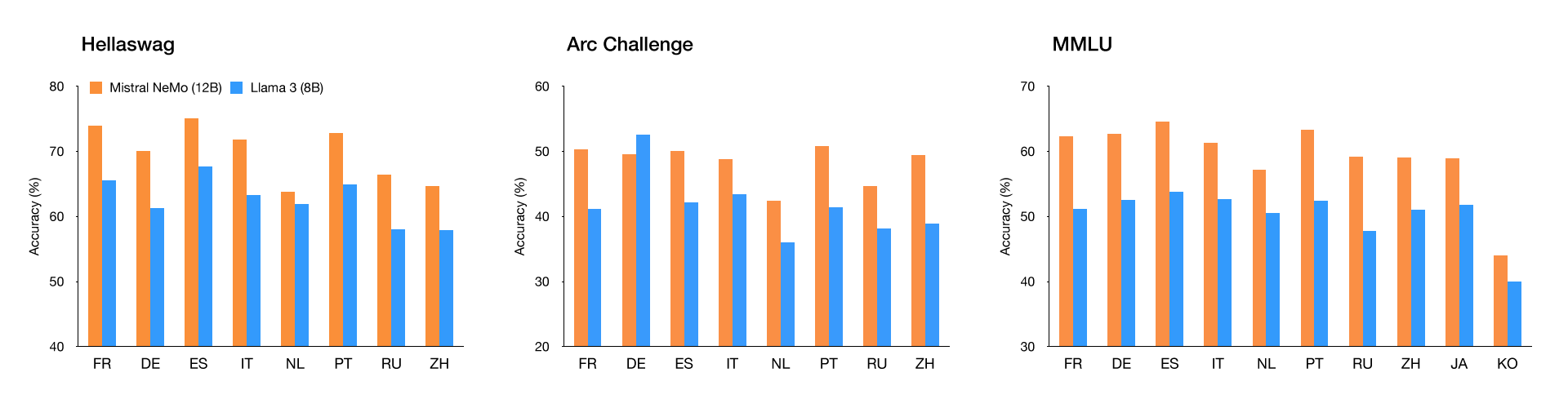
Mistral AI 宣布发布 Mistral NeMo,这是一个由 NVIDIA 协作开发的 12B 参数模型,具备高达 128k 令牌的上下文窗口。
该模型旨在支持企业应用,包括聊天机器人、多语言任务、编码和摘要。在其尺寸类别中,Mistral NeMo 在推理、世界知识和代码准确性方面均处于领先地位。使用标准架构,Mistral NeMo 易于使用,可作为任何使用 Mistral 7B 系统的直接替代品。
Microsoft Designer 与 Microsoft 产品无缝集成,包括 Word 和 PowerPoint,通过 Microsoft Copilot 进一步提升创意体验。订阅 Copilot Pro 后,当你在 Word 和 PowerPoint 中时,可以在你的工作流程中直接创建图像和设计。在 Word 或 PowerPoint 中,点击 Copilot 图标并描述你想创建的图像。在即将推出的 Word 版本中,你甚至可以请求创建文档横幅,并根据文档内容为你生成设计。
该模型支持包括普通话在内的 32 种语言,能为全球近 80%的地区提供高质量、低延迟的 AI 对话;
首次支持越南语、匈牙利语和挪威语;
重点提高了印地语、法语、西班牙语、普通话等 27 种语言的响应速度,其中英语速度提高了 25%,最高提升达 3 倍;
结合先进技术和低延迟模型架构,可快速合成语音,保持流畅自然且高品质的音质,响应时间不超 400 毫秒。
港中大(深圳)联合中科院声学所、上海人工智能实验室等机构发布了超过10万小时包含6种语言的多样化的语音生成数据集—— Emilia!
Emilia是一个开源的多语种外语音数据集,专为大规模语音生成研究设计。它包含超过101,000小时的六种语言高质量语音数据和相应的文本转录,覆盖了各种说话风格和内容类型,如脱口秀、访谈、辩论、体育评论和有声书。
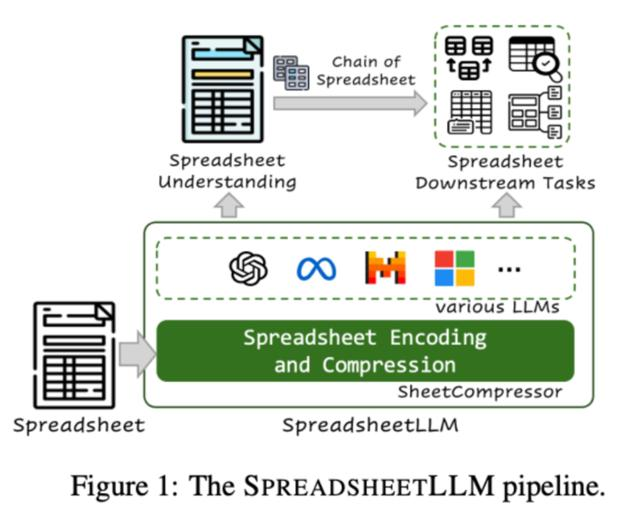
微软发布了一个新的大型语言模型,计划为 Excel、 Sheets 等电子表格应用程序开发全新的 AI 大语言模型–SpreadsheetLLM。
Microsoft在论文指出,SpreadsheetLLM作为一款全新的AI模型,将广泛使用于理解和处理但复杂的电子表格数据。
或许会让会计师和数据分析师们对他们的未来工作前景感到担忧。网友们在社交平台X上调侃,认为“凯伦的工作很快就会被人工智能取代”。
H2O.ai 凭借最新的 Danube3-4B 版本超越苹果并与微软竞争,在 10 次 HellaSwag 基准测试中实现了超过 80% 的准确率
新发布的 H2O-Danube3 现已在 Hugging Face 上全球发售。 H2O SLM 系列的最新成员包括 H2O-Danube3-4B 和 H2O-Danube3-500M 型号
etect-2B的子模型由带有关键层插入适配模块的冻结音频表示模型组成。这些适配模块专注于识别真实音频与伪造音频的细微差别——即录音中不经意留下的声音痕迹。大多数AI生成的音频片段听起来都“过于完美”。Detect-2B能够预测音频中AI制作的成分,而且无需每次听到新片段时都重新训练模型。这些子模型也经过了大型数据集的充分训练。
经过数月的测试,亚马逊今天向所有美国客户推出了其生成式人工智能购物助手Rufus。这个对话式购物助手旨在帮助客户节省时间并做出更明智的购买决策。
Rufus现已在亚马逊购物应用中上线,恰逢Prime Day
StreamVC 即使在移动平台上也能以低延迟从输入信号生成结果波形,使其适用于呼叫和视频会议等实时通信场景,并解决这些场景中的语音匿名等用例。
谷歌的设计利用 SoundStream 神经音频编解码器的架构和训练策略来实现轻量级高质量语音合成。
谷歌证明了因果学习软语音单元的可行性,以及提供白化基频信息以提高音调稳定性而不泄漏源音色信息的有效性。
RenderNet Al是一款强大的图像生成工具,专注于创建一致的角色,
并控制其姿势、构图和风格,现在推出了视频换脸功能..
这款 AI 视频换脸工具非常强大
Flawless 是一家人工智能驱动的电影制作工作室,希望您在观看热门节目的同时还能在晚上安然入睡(不会出现不匹配的嘴巴动作和残酷的场景剪辑)。 Flawless 的专有技术 TrueSync 于 2018 年由多才多艺的导演斯科特·曼 (Scott Mann) 和尼克·莱恩斯 (Nick Lynes) 创立,它可以在演员的脸部上进行映射,并提供我们在人工智能狂野西部见过的最令人印象深刻的翻译。
Stability AI宣布为其用户友好型聊天机器人Stable Assistant推出两项创新功能,进一步提升用户体验和创造力。这两项新功能分别是图片编辑中的搜索和替换,以及通过Stable Audio生成高质量音频。