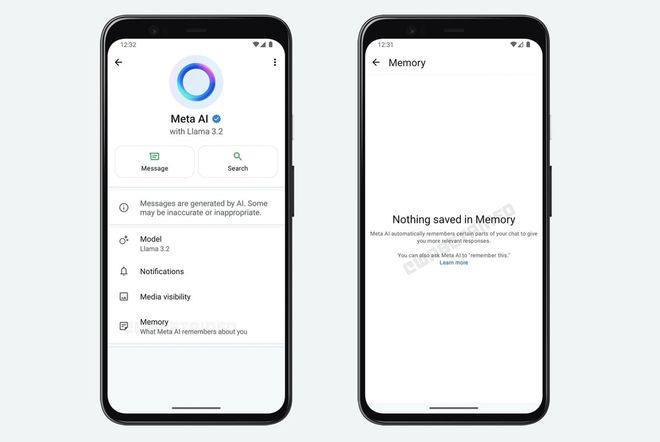
AI巨头, AI资讯, AI项目, Apple, MetaMeta 为 WhatsApp 引入 AI 机器人聊天记忆功能 22 1 月, 2025 Meta公司正在为旗下WhatsApp即时通信软件添…