它能够自动识别和定位图像中的各种对象 YOLO-Wo…
卡内基梅隆大学和苏黎世联邦理工学院的研究人员正在帮助…
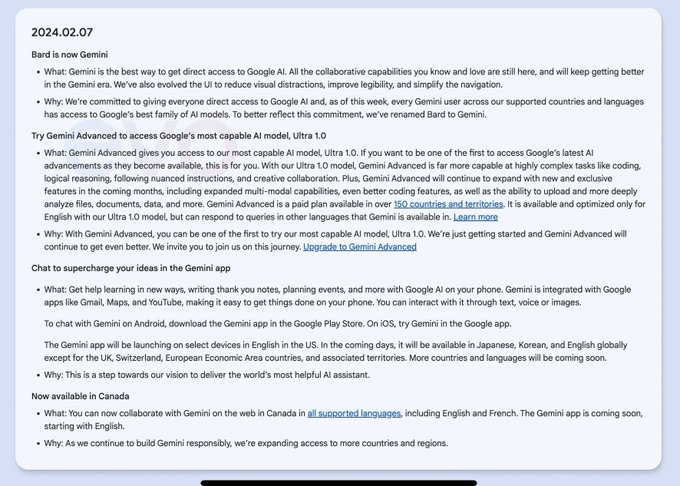
Google的Gemini Ultra模型将在2月7…
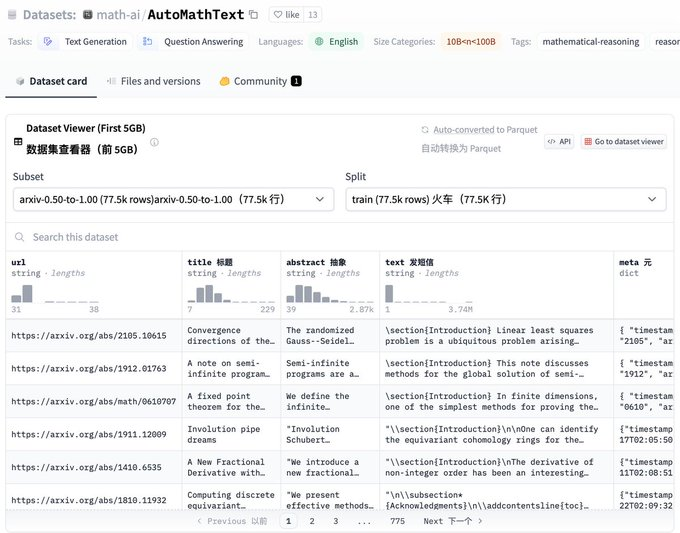
数据集包含来自不同来源的数据,如arXiv的科学论文…
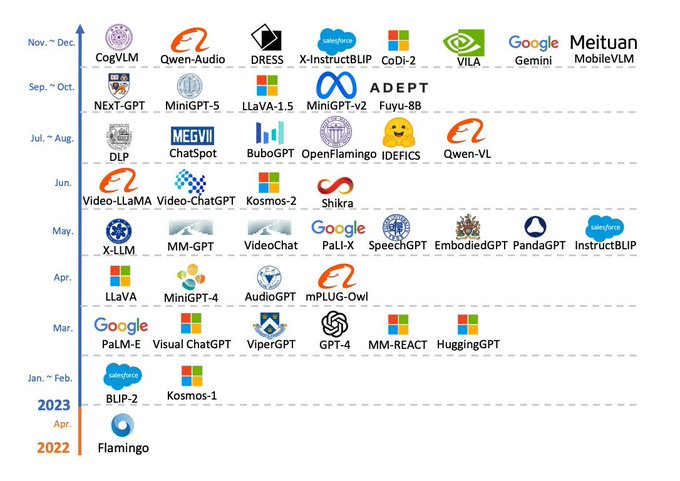
过去几周,多模态 LLMs(MM-LLMs)研究论文…
1、物体的准确放置:确保新插入的物体在视频中的位置看…
旨在从公元 79 年维苏威火山喷发埋藏的烧焦卷轴扫描…
模型有1.2亿个参数,经过了10万小时的语音数据训练…
它提供了一个拖放式的界面,允许用户轻松地创建复杂的图…
通过你的提示生成有声读物 提供在线链接,帮你朗读在线…
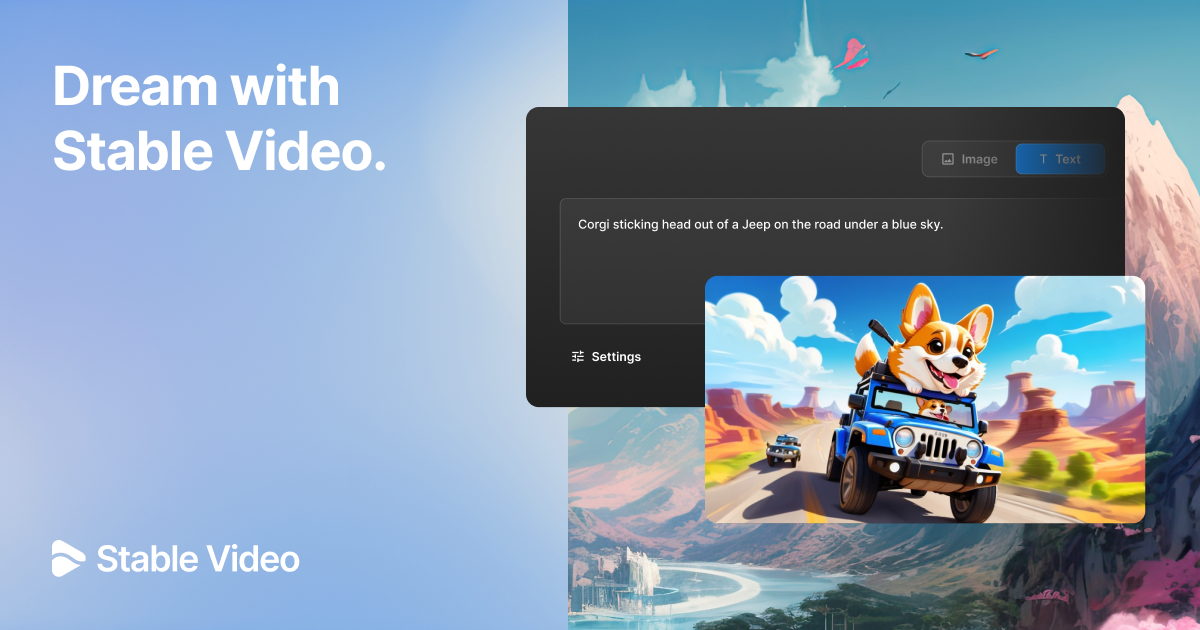
可以看出Stable Video在处理动作场景,尤其…
谷歌在Bard谷歌地图和Imagen-2升级,亚马逊…