支持英语、西班牙语、法语、中文、日语和韩语等多种语言…
OpenAI的技术报告里 有一个地方可以提前体验So…
感觉像是可视化的维基百科,就是你搜索关键词,它会搜索…
Move API提供的功能和灵活性为开发者创造了广泛…
与英语语言/翻译文件、图像生成样式图像、工作区设置….
边打字边生成图片,速度贼拉快
之前的YOLO系列模型相比,YOLOv9在不牺牲性能…
1、分辨率提升:将图像升级到4K分辨率,无论原始图像…
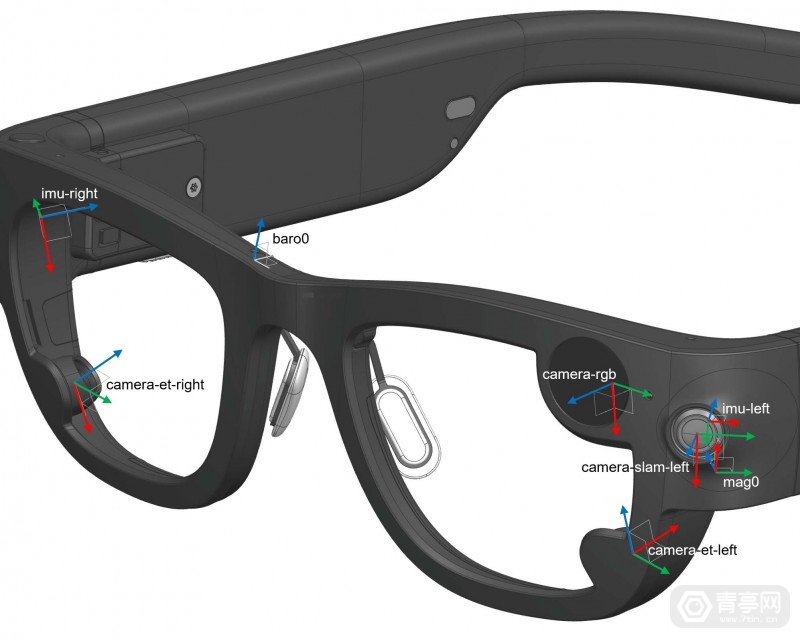
一个基于 Project Aria AR眼镜记录的第…
实时检测视频中的特定对象,然后分割对象,使用自然语言…
UMI可以将人类在复杂环境下的操作技能直接转移给机器…
YOLOv8能够在图像或视频帧中快速准确地识别和定位…