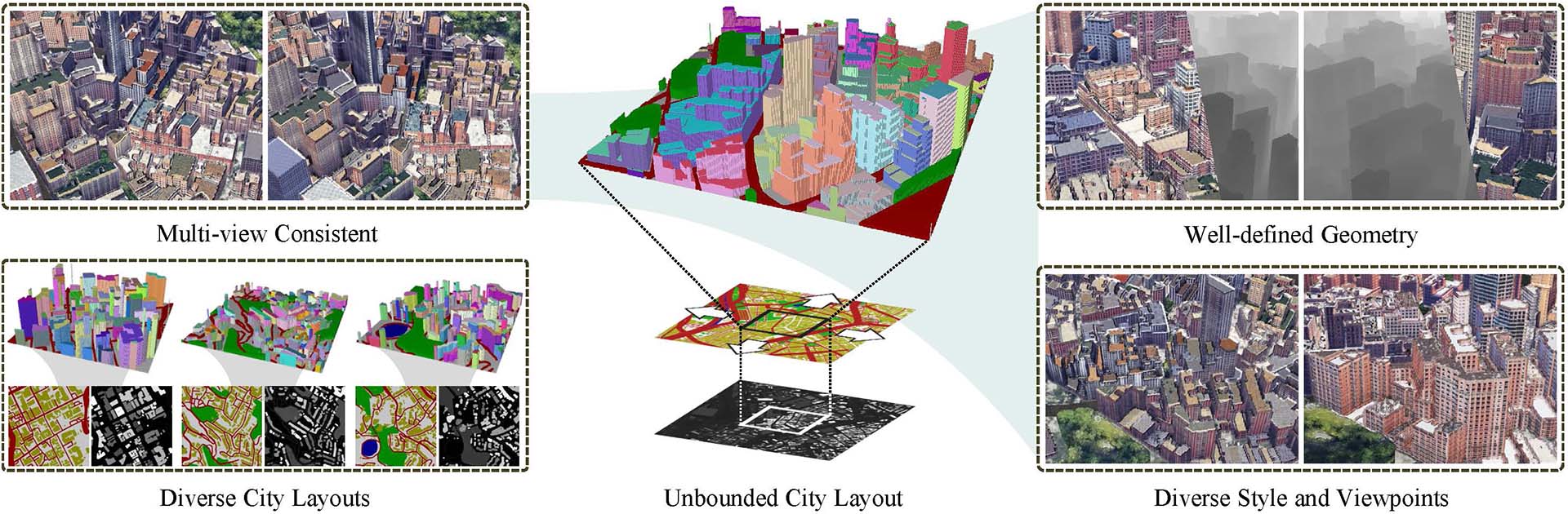
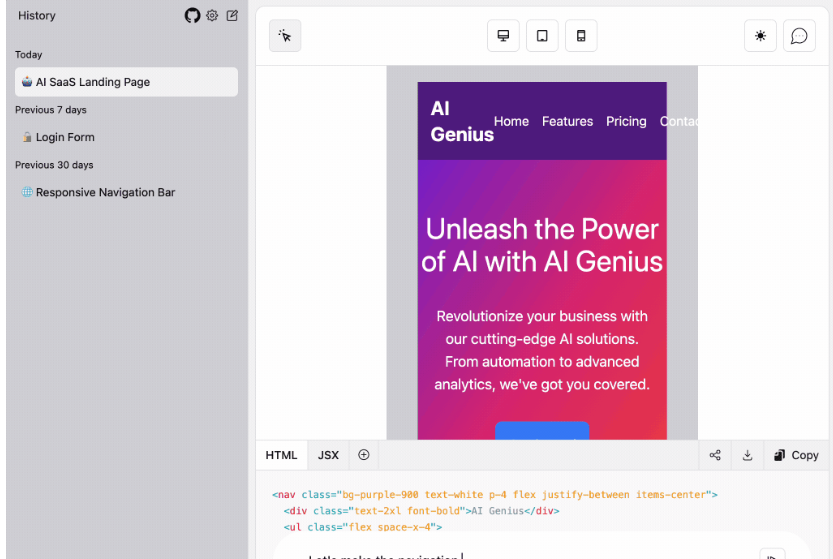
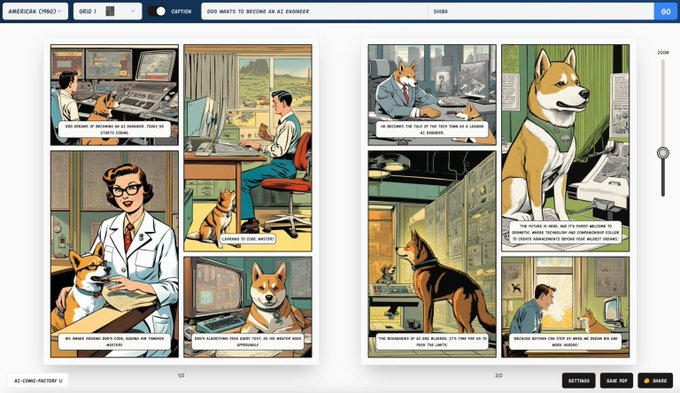
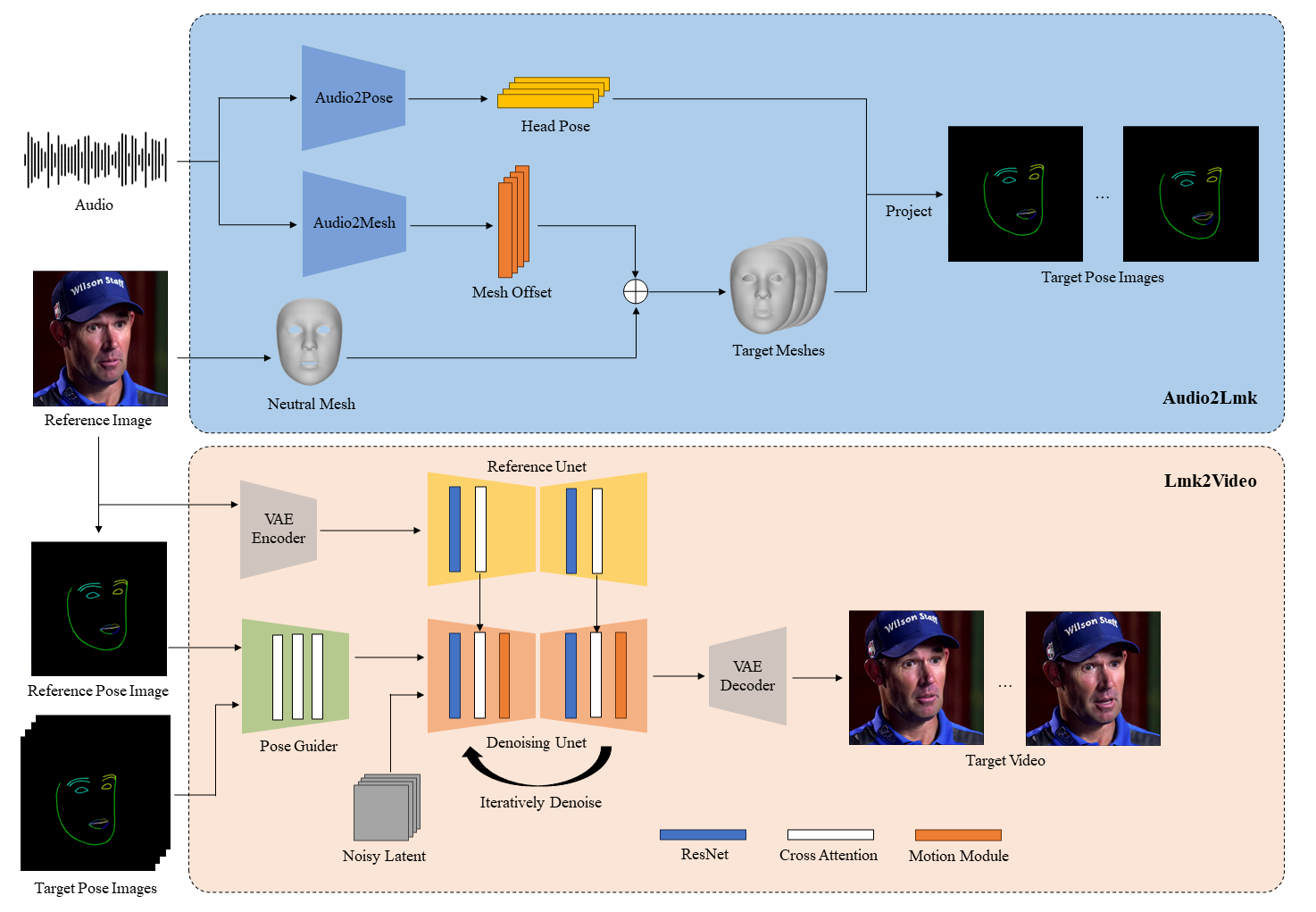
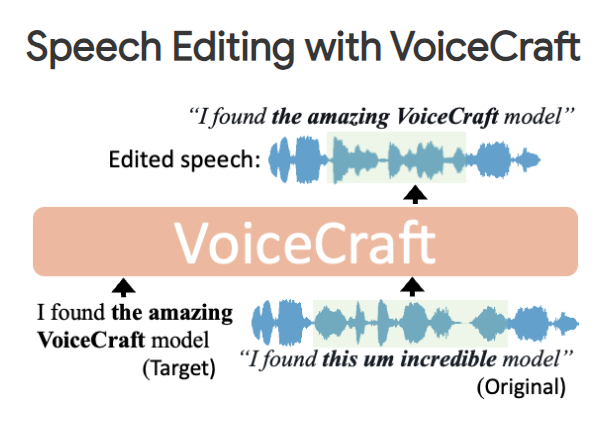
AI项目, 开源项目Awesome-Generative-AI-Guide: 一站式AI最新研究更新、面试资源、免费课程等综合库 17 4 月, 2024 最新研究更新:提供每月最佳生成式AI论文列表,包括各…