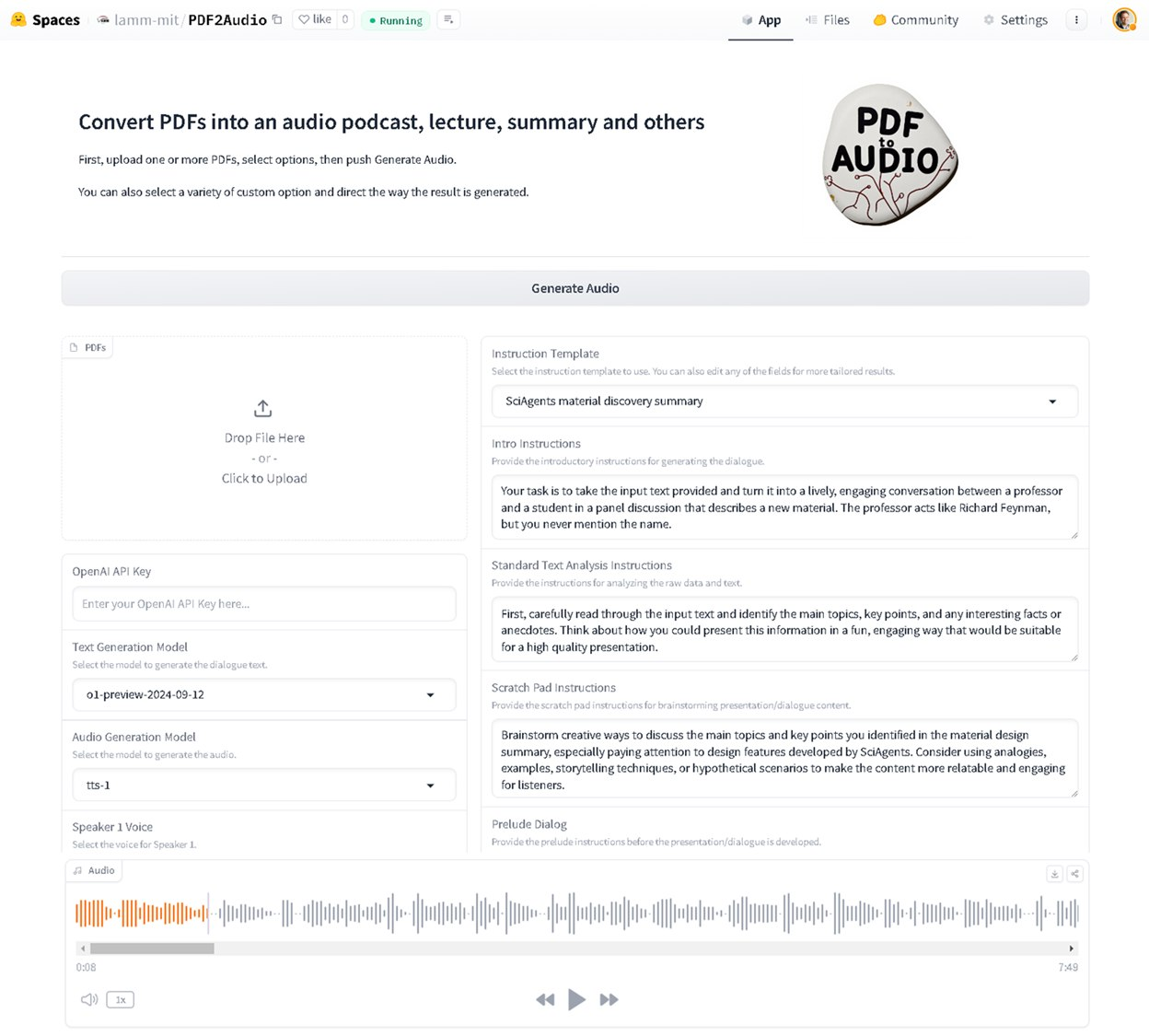
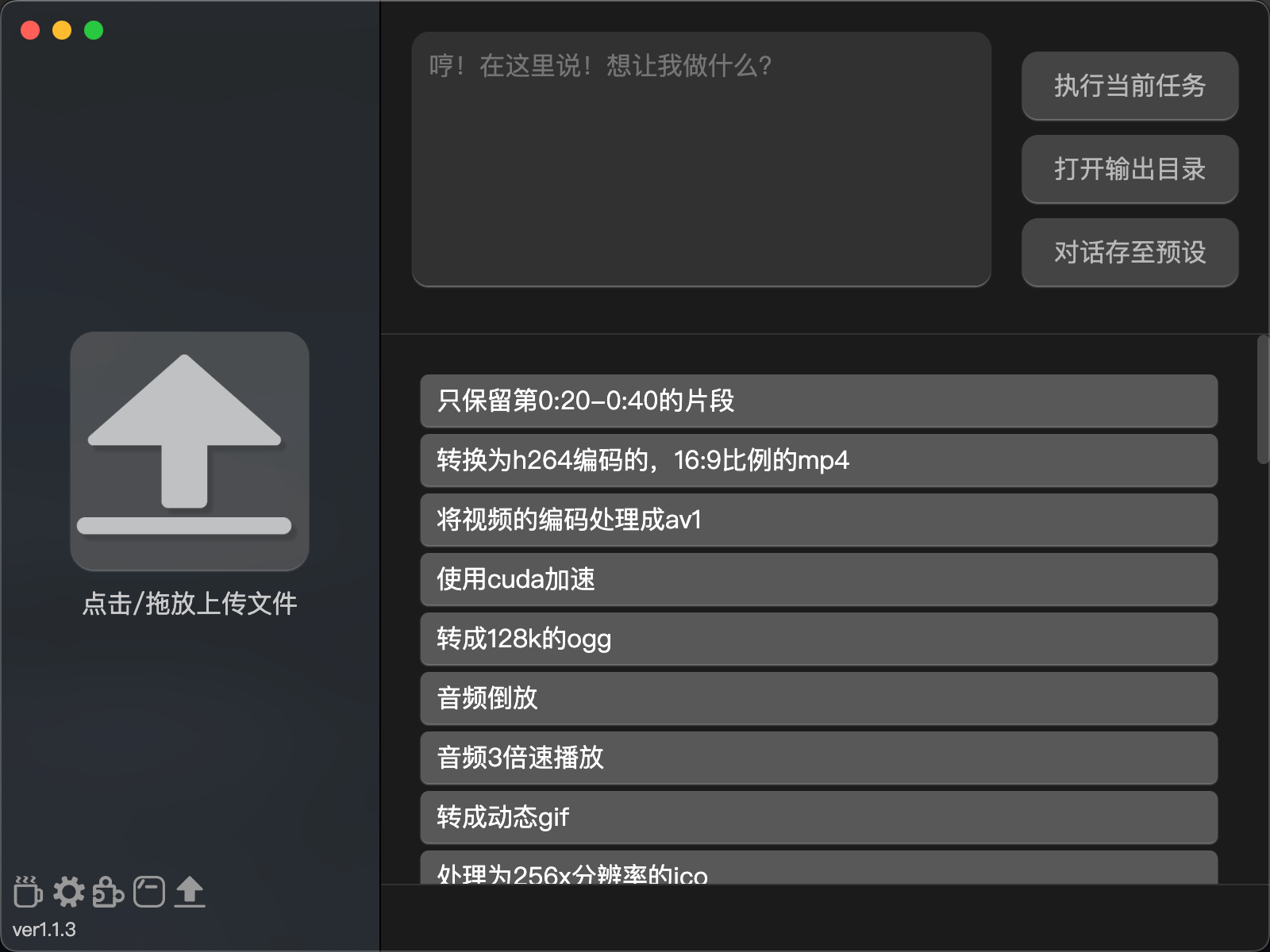
AI巨头, AI行业应用, AI项目, OpenAI, 多媒体处理, 开源项目ChatGPT API SRT 字幕翻译器 26 9 月, 2024 此工具采用OpenAI ChatGPT API进行文…