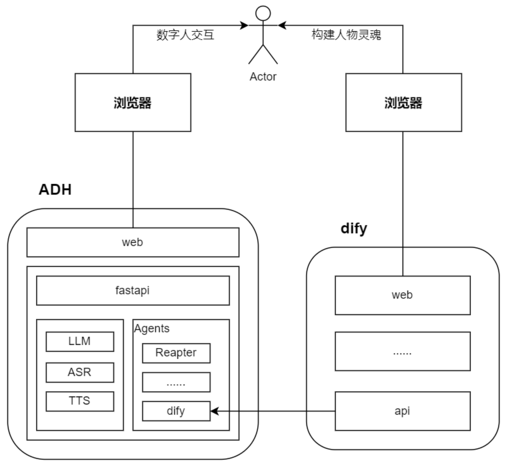
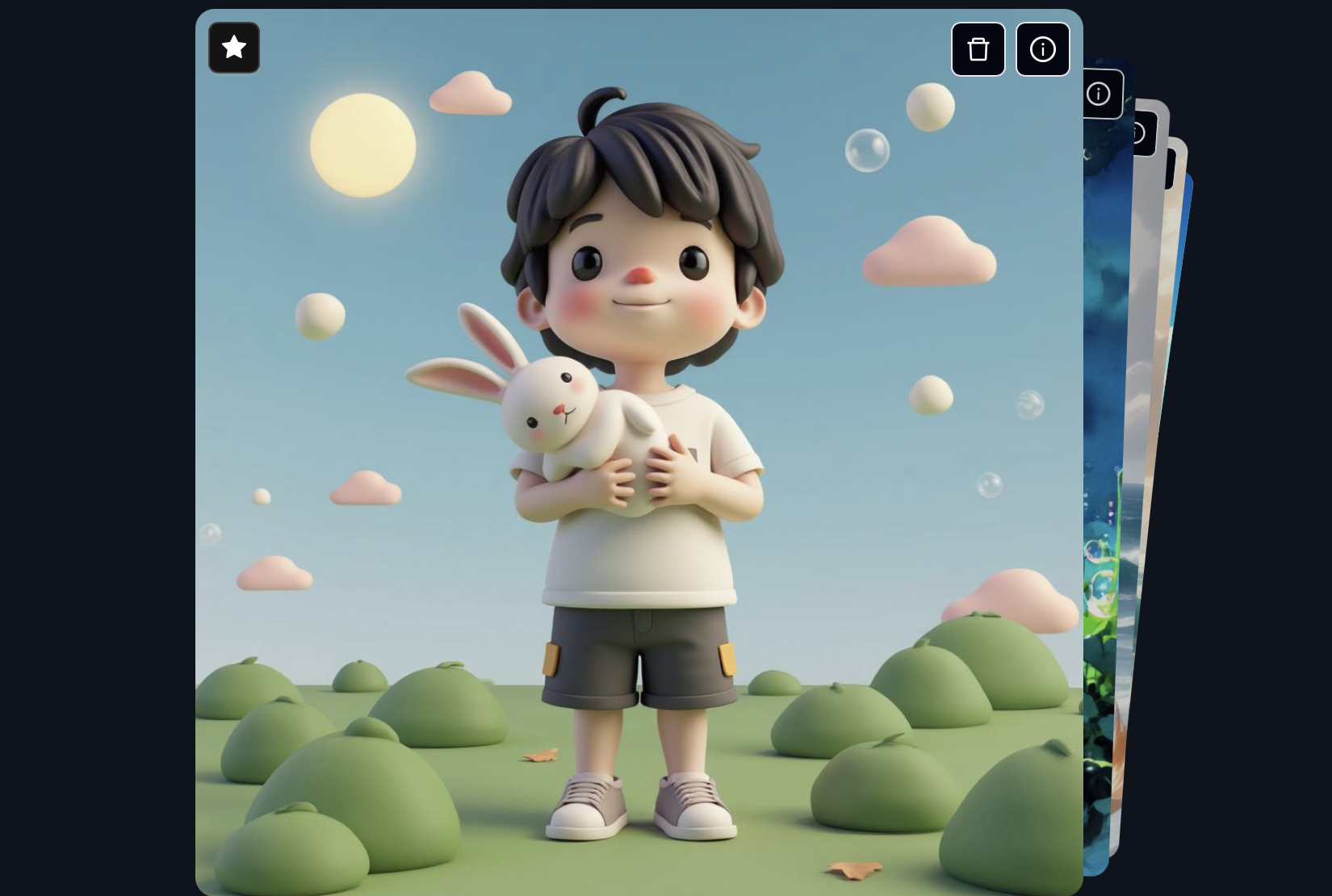
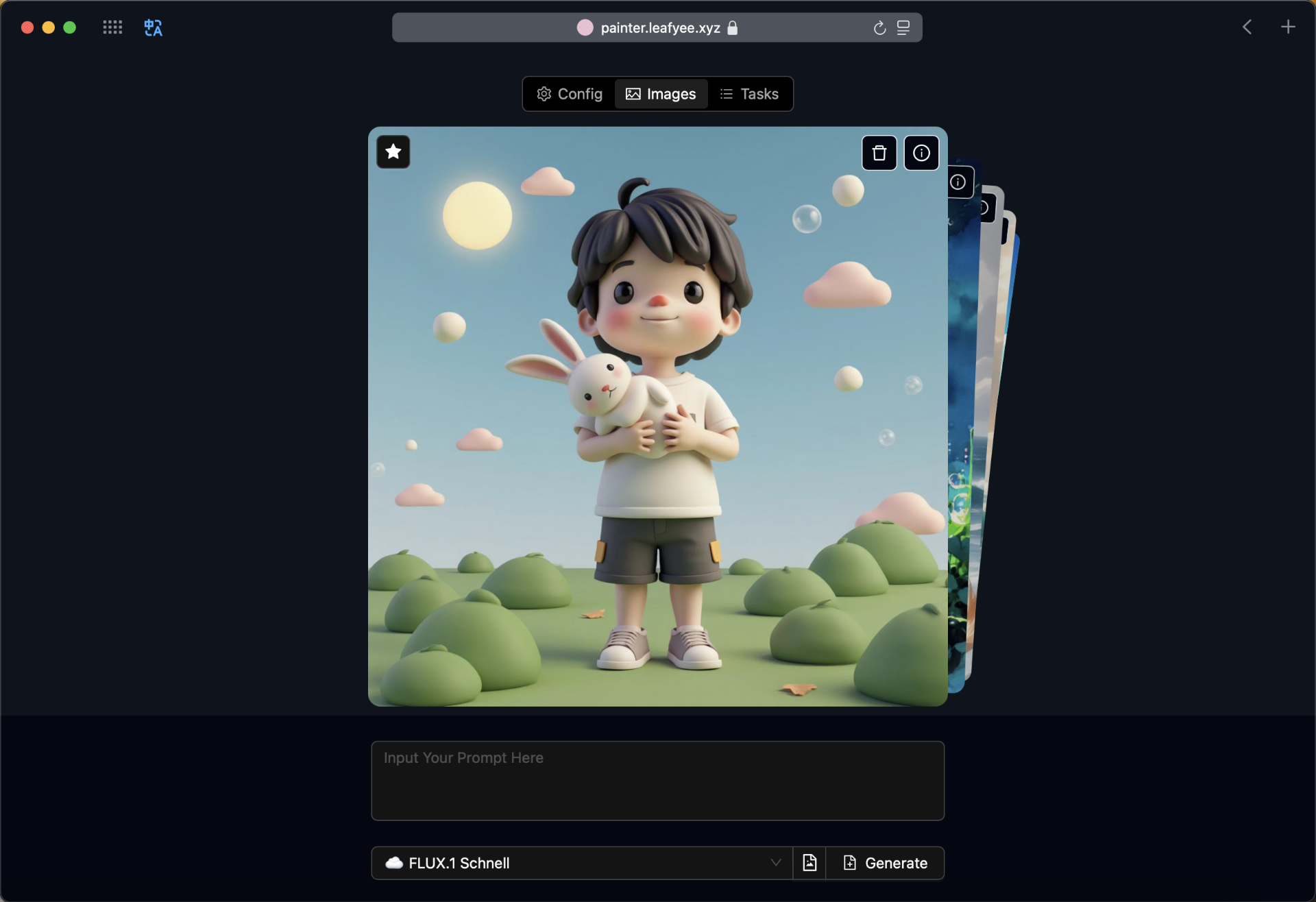
AI巨头, AI行业应用, AI项目, Nvdia, 多媒体处理, 开源项目Sana:高效的文本到图像生成框架,能够生成4K高清图像 1 3 月, 2025 Sana 是 NVIDIA 发布的一个开源项目,专为…