深入解析大型语言模型后训练方法项目介绍
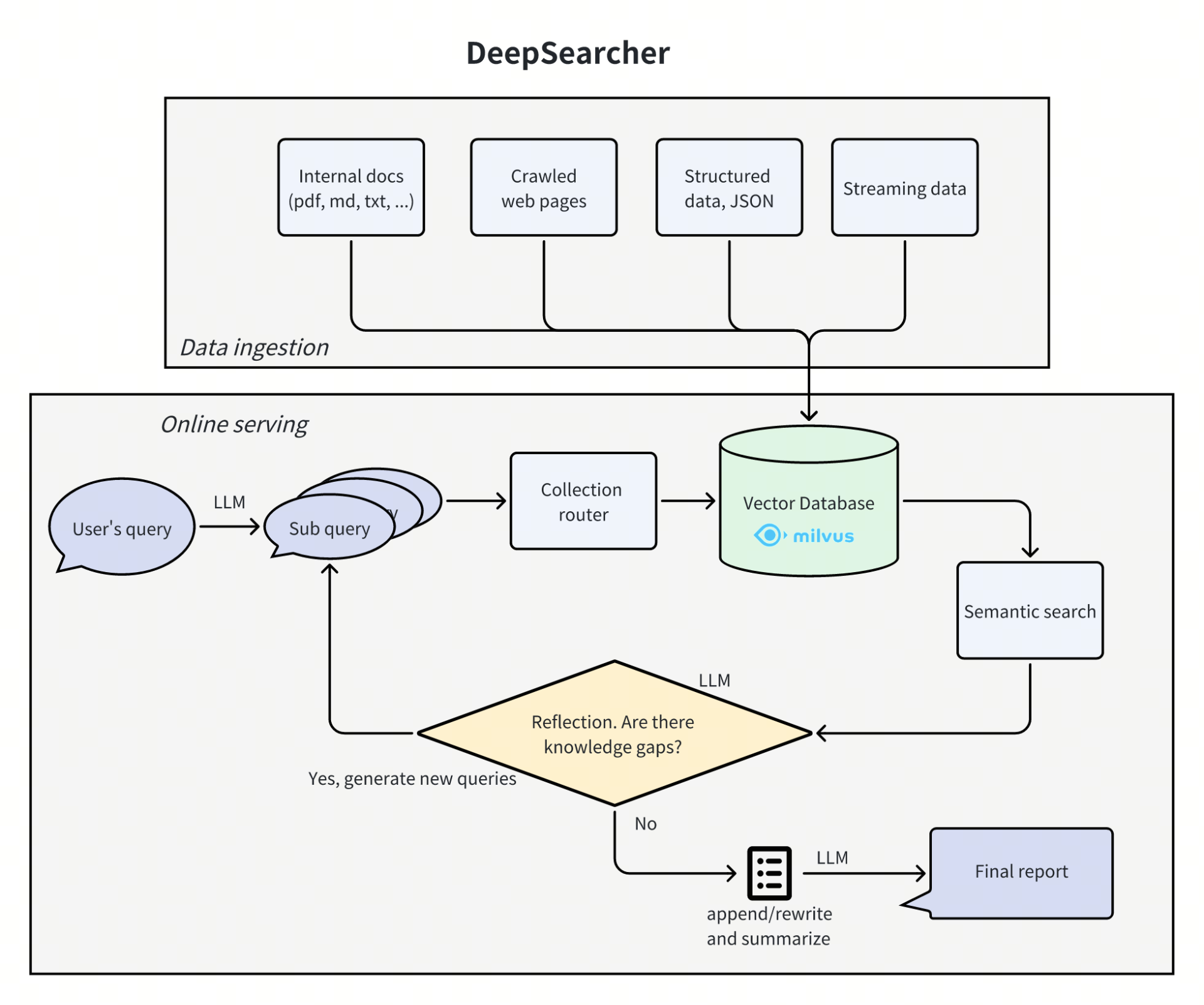
一个专门收集和研究大型语言模型(LLM)后训练方法论的资源库,包括论文、代码实现、基准测试和社区资源。该资源库涵盖了从基础研究到实际应用的各个方面,包括大语言模型的 reasoning 能力、强化学习、测试时间扩展方法
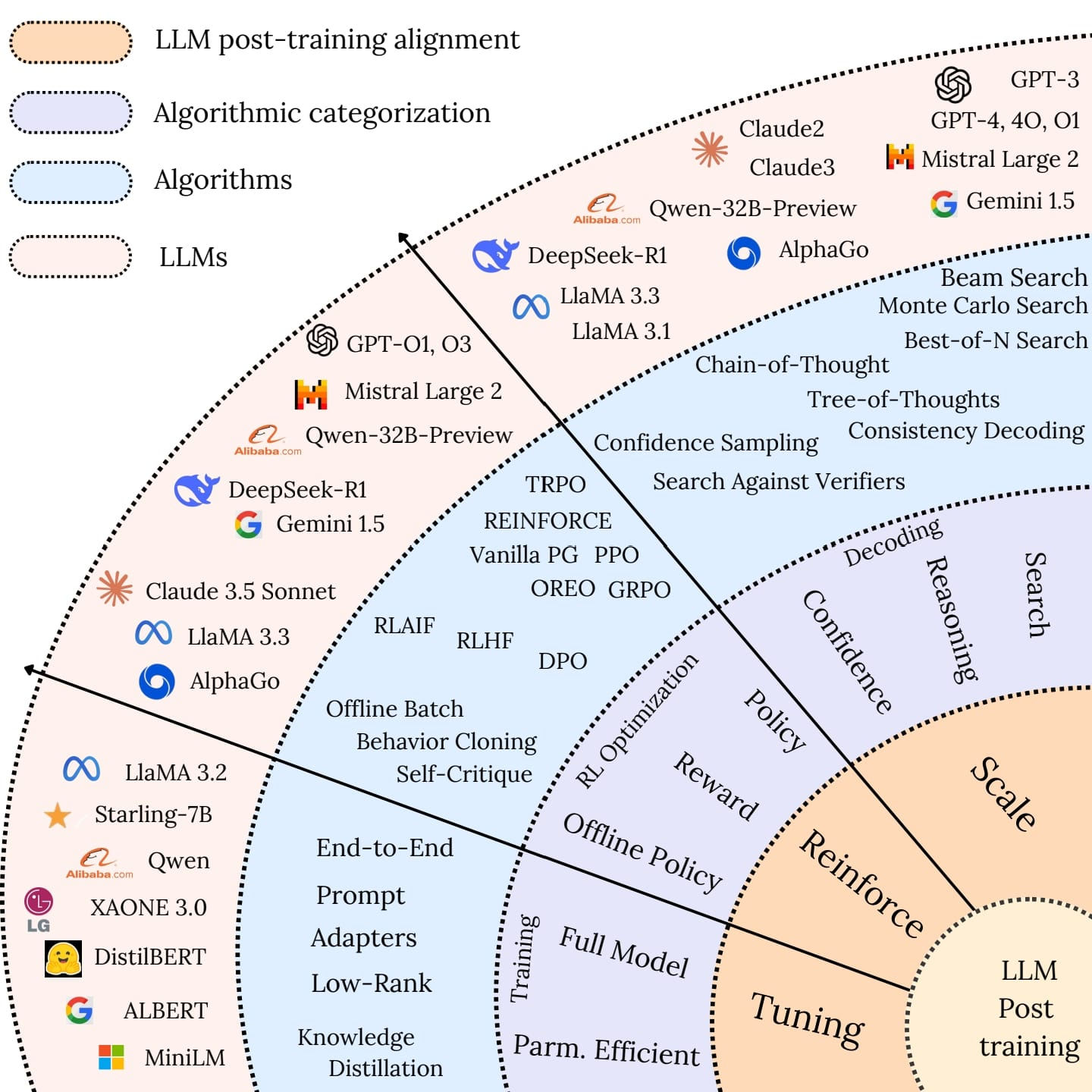
一个专门收集和研究大型语言模型(LLM)后训练方法论的资源库,包括论文、代码实现、基准测试和社区资源。该资源库涵盖了从基础研究到实际应用的各个方面,包括大语言模型的 reasoning 能力、强化学习、测试时间扩展方法

AimeBox是一款基于Langchain和Electron开发的多平台桌面聊天客户端,旨在为用户提供全离线、本地可执行的智能代理体验。该项目支持本地知识库、工具调用以及多个智能代理的集成,满足用户在不同场景下的多样化需求。

Saber-Translator是一款专为漫画爱好者设计的AI翻译工具,旨在帮助用户轻松跨越语言障碍,享受原汁原味的日文漫画。该工具利用先进的AI技术,智能检测漫画中的对话气泡,精准识别日文文本,并快速翻译成流畅自然的中文。
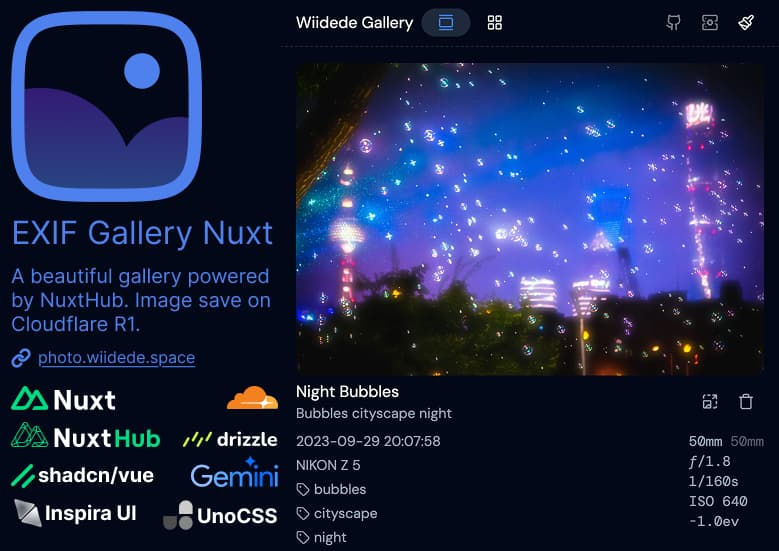
exif-gallery-nuxt 是一个基于 Nuxt.js 构建的照片画廊应用,支持解析和展示照片的 EXIF 元数据。该项目结合了 Vue.js 和 Nuxt.js 的优势,为用户提供一个动态、高效的照片管理和浏览体验。

在人工智能迅速发展的今天,智能聊天助手正在成为提升团队协作和工作效率的重要工具。HiveChat 是一款开源的 AI 聊天应用,专为 中小型团队 设计,旨在提供更智能、高效的沟通方式。

语言障碍和字幕制作的高成本限制了全球观众对优质视频内容的获取。
为了解决这一难题,隆重推出 VideoLingua
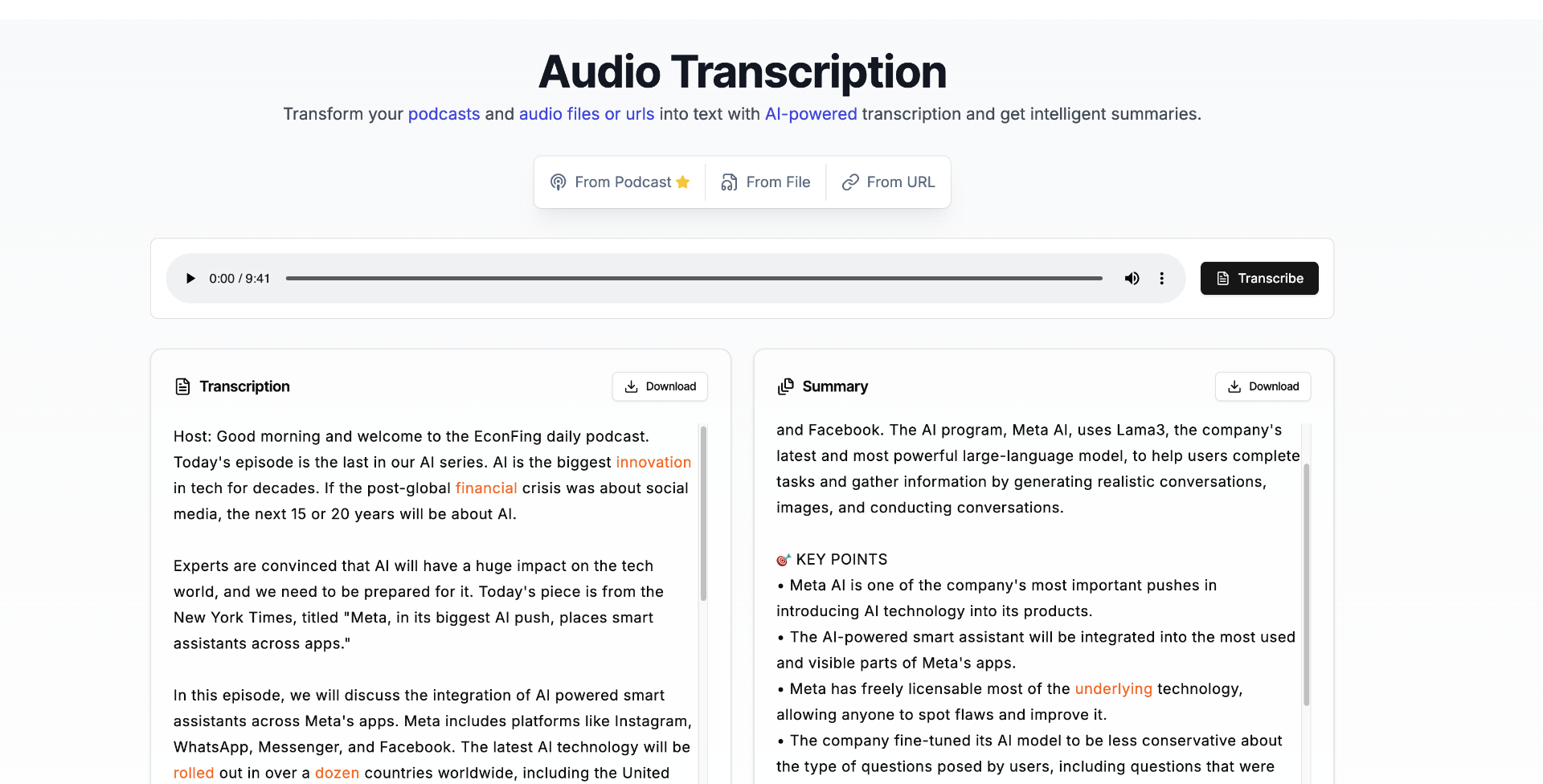
:一个基于 Next.js 和 OpenAI Whisper API 的播客转录应用,支持音频文件转录和智能摘要生成。
支持音频文件上传和 URL 输入两种方式、支持小宇宙播客音频转录、支持转录文本和摘要的下载,内置音频播放器,现代化的 UI 设计。

为大家介绍一款名为NeoAI的开源工具。NeoAI旨在通过简单的自然语言指令,让用户无需编写代码即可控制计算机,实现文件管理、任务自动化、定时操作和跨平台设备控制等功能。

SQLChat 是一个开源的 SQL 聊天助手,旨在帮助用户通过自然语言与数据库交互,使 SQL 查询变得更加直观和高效。它能够理解用户的意图,并自动生成相应的 SQL 语句,适用于数据库管理、数据分析等场景。
Private-ASR 是一个基于开源项目 FunClip 修改的本地部署工具,集成了自动语音识别(ASR)、说话人分离、SRT 字幕编辑以及基于大型语言模型(LLM)的总结功能。
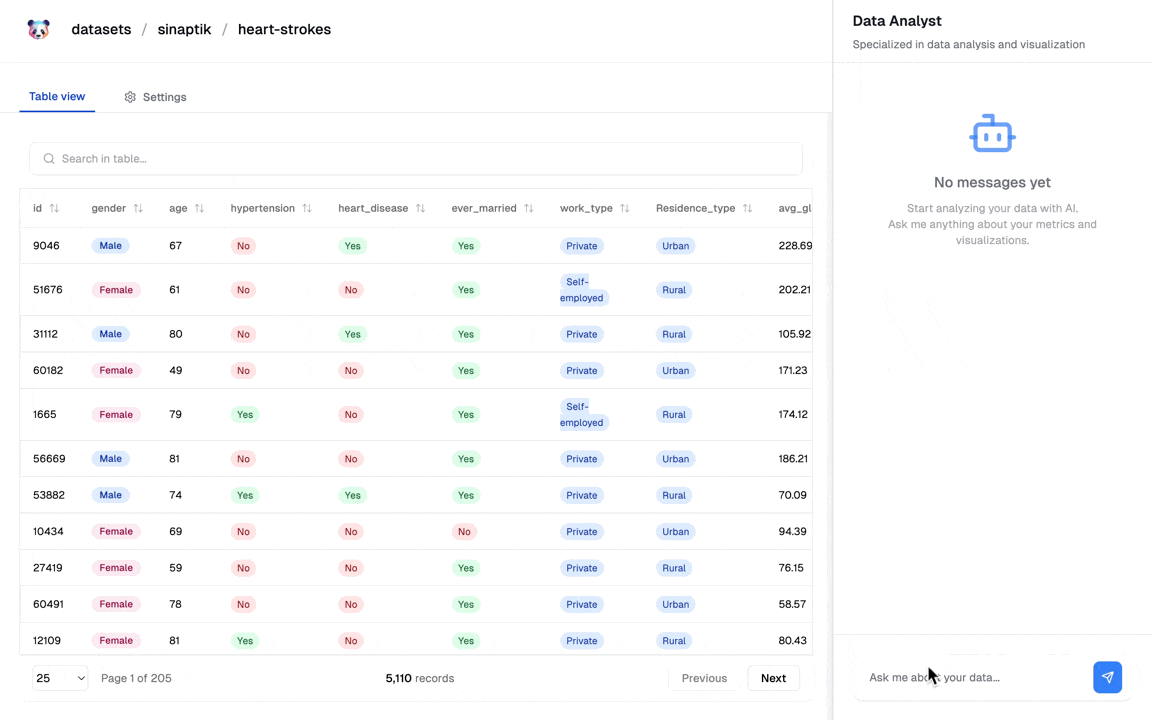
PandasAI 是一个开源的 Python 库,旨在为流行的数据分析和处理工具 pandas 添加生成式人工智能(Generative AI)功能。它使用户能够通过自然语言查询与数据进行交互,使数据分析变得更加对话化和直观。