Tarogo Cloud

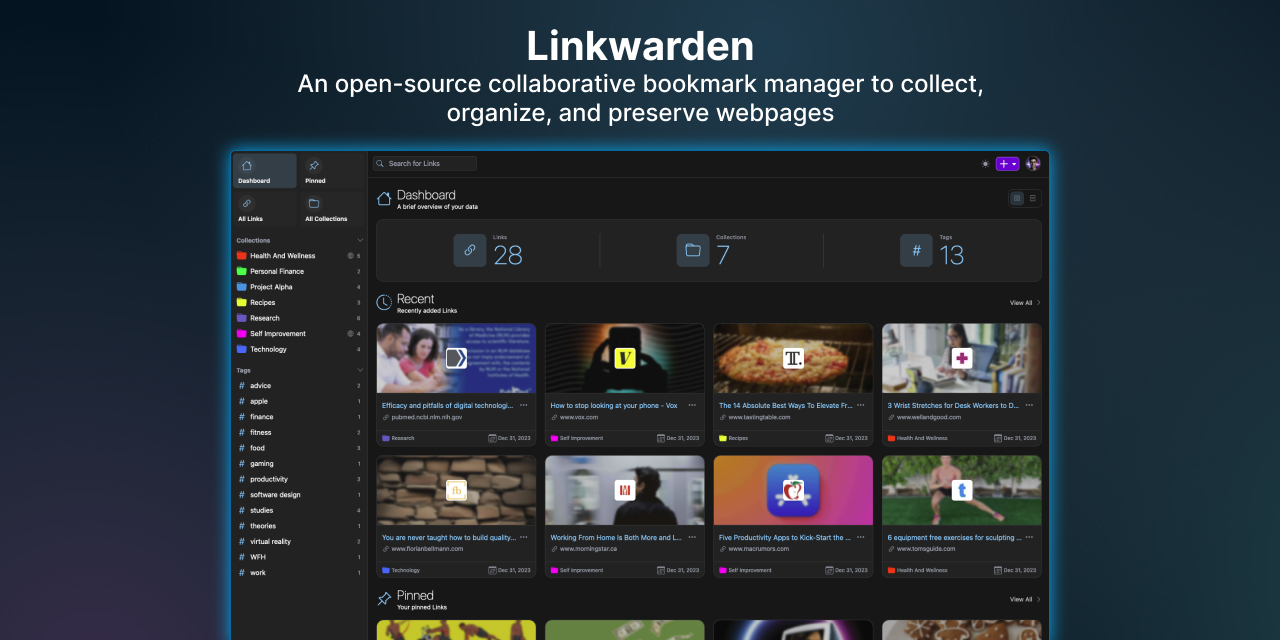
开源的服务:Linkwarden可以创建分类、标签
颜值还挺高,可以创建分类、标签,使用官方提供的浏览器扩展一键添加书签,最后还可以转换成图片、PDF、Readable 格式进行阅读或分享。
Google Gemini API Cookbook
Google 官方Gemini API提供的指南和示例集合
帮助开发者更好地理解和使用Gemini API,包括如何构建应用程序、编写提示以及利用API的不同特性。
Synclabs发布新版的唇型同步模型:Sync-1.6.0
新版模型进行了唇形同步升级,能够产生平滑、准确的唇形,同时减少视频帧之间的闪烁现象
SyncLabs构建了基于给定音频条件生成视频的音视频模型。

Gatekeep:一个新型的文本转视频 AI,专注与教学
它可以通过文本提示将数学、物理问题转换成视频内容
它会自动生成包括图表、图示、动画原理,还包含讲解内容的2分钟左右的视频。
能非常直观的帮助你了解一些知识和原理。




适用于任何分辨率特征的模型无关框架
深层特征是计算机视觉研究的基石,它捕获图像语义并使社区即使在零样本或少样本情况下也能够解决下游任务。
然而,这些功能通常缺乏空间分辨率来直接执行分割和深度预测等密集预测任务,因为模型会积极地池化大区域的信息。

可以直接通过文字描述让任何静态图动起来
而且能做各种动作,跳舞什么的都是小case…
最牛P的是,他们的模型能能理解真实世界的物理运动原理,所以出来的视频很真实。
不仅如此,它还能直接文字生成视频,进行各种角色混合和动作替换…

令人兴奋的新研究警报-𝐏𝐢𝐱𝟐𝐏𝐢𝐱-𝐓𝐮𝐫𝐛𝐨
这些条件 GAN 能够采用文本到图像模型(例如 SD-Turbo),通过一步(A100 上为 0.11 秒,A6000 上为 0.29 秒)进行配对和不配对图像转换。尝试我们的代码和 @Gradio 演示。

Creatie这个AI-UI设计工具
有点强啊,做的相当完整,基本上可以当做一个加上了 AI 功能的 FIgma。
而且全部都是免费的,AI 能力也很强,选择区域输入需求直接就会展示对应备选的组件,你可以自己拼装和修改,还能使用自己的设计系统。


Open-Sora开源了
包括完整的文本到视频模型训练过程、数据处理、训练细节和模型检查点。
该项目由@YangYou1991 团队开发 这是 OpenAI Sora 在视频生成方面的开源替代方案。
可以在仅仅3天的训练后生成2~5秒的512×512视频。

基于真实果蝇行为训练的人工智能模型
通过结合解剖学精确的模型、物理模拟器和基于真实果蝇行为训练的人工智能模型
@HHMIJanelia 和 @GoogleDeepMind
的科学家创造了一种计算机化昆虫,它能够像真实果蝇一样,在复杂的轨迹上行走和飞行。