AI巨头

Google Gemini API Cookbook
Google 官方Gemini API提供的指南和示例集合
帮助开发者更好地理解和使用Gemini API,包括如何构建应用程序、编写提示以及利用API的不同特性。


Open-Sora开源了
包括完整的文本到视频模型训练过程、数据处理、训练细节和模型检查点。
该项目由@YangYou1991 团队开发 这是 OpenAI Sora 在视频生成方面的开源替代方案。
可以在仅仅3天的训练后生成2~5秒的512×512视频。


MusicLang-基于 Llama 2 的音乐生成模型!
基于 Llama2,从头开始训练。
许可 – 开源。
优化在 CPU 上运行。 🔥
高度可控,可选择节奏、和弦进行、小节范围等等!
Claude3最新已经上线AWS
Anthropic太牛了。Claude-3 发布的两件事:
领域专家基准。我对饱和的 MMLU 和 HumanEval 不那么感兴趣。Claude特别挑选了金融、医学和哲学作为专家领域并报告性能。我建议所有 LLM 模型卡都遵循这一点,这样不同的下游应用程序就会知道该期待什么。
拒绝率分析。LLMs’对无辜问题过于谨慎的回答正在成为一种流行病。Anthropic 通常处于极端安全的一端,但他们认识到了这个问题,并强调了他们在这方面的努力。好极了!
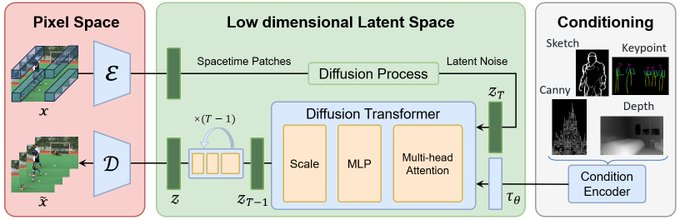
北京大学Yuangroup团队发起了一个 Open-Sora计划
旨在复现OpenAI 的Sora模型
Open-Sora计划通过视频VQ-VAE、Denoising Diffusion Transformer和条件编码器等技术组件,来实现Sora模型的功能。

ChatMusician: 能够理解和生成音乐的大语言模型
通过根据给定的文本提示、和弦序列、旋律线索、音乐主题或形式等条件。
ChatMusician能自动生成结构完整、风格多样的音乐作品。
包括单声部旋律、和声编配,乃至完整的乐曲结构设计。
同时它还能理解和分析音乐理论的各个方面。


OpenAI推出的一音乐生成模型:Jukebox
OpenAI在2019年8月份就推出了他们的一音乐生成模型:Jukebox
Jukebox能够根据提供的歌词、艺术家和流派信息生成多种流派和艺术家风格的完整音乐和人声歌曲。
最牛P的是,3年前的质量就已经这样了…
而且据说Jukebox 2即将发布


Google发布了 Gemini-Pro-1.5
这是其 AI 模型的下一个版本,具有超过 1,000,000 个令牌上下文长度。
该模型现在可以一次性理解整本书、整部电影和播客系列。
这远远超过了所有其他竞争对手的聊天机器人上下文窗口。

OpenAI 和 Elon Musk \[译\]
OpenAI 的使命是确保全人类能从人工通用智能 (AGI) 中受益,这不仅意味着我们要构建既安全又有益的 AGI,也意味着我们要努力创造广泛分布的利益。现在,我们将分享我们如何实现这个使命的理解,以及我们与 Elon 的关系的一些事实。我们打算驳回 Elon 的所有主张

OpenAI Sora的新文本到视频模型
Sora 是一个数据驱动的物理引擎。它是对许多世界的模拟,无论是真实的还是幻想的。模拟器通过一些去噪和梯度数学来学习复杂的渲染、“直观”物理、长期推理和语义基础。
如果 Sora 使用虚幻引擎 5 对大量合成数据进行训练,我不会感到惊讶。它必须如此!