OpenAI公布了超级对齐项目一项最新研究成果,探索了一种新方法:
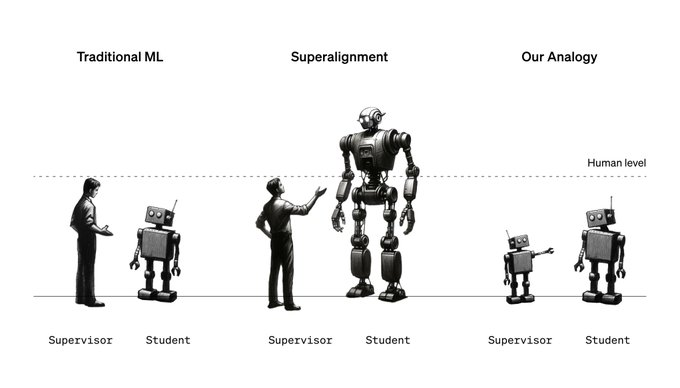
这项研究的目的是为了解决一个问题:未来,当 AI 变得比人类更聪明时,人类如何能够有效地控制这些 AI。
这项研究的目的是为了解决一个问题:未来,当 AI 变得比人类更聪明时,人类如何能够有效地控制这些 AI。
你只需要提供一张人物的静态照片和一段语音录音,VividTalk就能将它们结合起来,制作出一个看起来像是实际说话的人物的视频。
这个模型统一了之前的三个Seamless系列模型,可以实时翻译100多种语言,延迟不到2秒钟,说话者仍在讲话时就开始翻译。
该工具允许用户通过文本输入生成逼真的会说话的真人视频。你只要上传想要化身模仿的人的照片,并写一个剧本。
你只需要上传一首歌,然后描述你想要的风格或感觉,这个工具就能自动帮你把歌曲改编成新的风格,创造出一个全新的混音版本。
用户只需要进行简单的设置和安装步骤,就可以在本地(即自己的Macbook上)运行GitHub Copilot,并且可以在没有网络连接的情况下使用。
AudioSep可以从任何混合的音频信号中提取出特定的声音成分并分离出来。与传统的声音分离模型不同,AudioSep允许用户通过自然语言描述来指定他们想要分离的声音。
该模型生成的人体图像不仅逼真,而且具有高度的三维结构感,它能理解图像背后的三维结构。就像你不仅看到一个人,还能感知他站立的方式、面部的轮廓等。