这家人工智能公司希望彻底改变将对话重新配音成不同语言的方式
Flawless 是一家人工智能驱动的电影制作工作室,希望您在观看热门节目的同时还能在晚上安然入睡(不会出现不匹配的嘴巴动作和残酷的场景剪辑)。 Flawless 的专有技术 TrueSync 于 2018 年由多才多艺的导演斯科特·曼 (Scott Mann) 和尼克·莱恩斯 (Nick Lynes) 创立,它可以在演员的脸部上进行映射,并提供我们在人工智能狂野西部见过的最令人印象深刻的翻译。
Flawless 是一家人工智能驱动的电影制作工作室,希望您在观看热门节目的同时还能在晚上安然入睡(不会出现不匹配的嘴巴动作和残酷的场景剪辑)。 Flawless 的专有技术 TrueSync 于 2018 年由多才多艺的导演斯科特·曼 (Scott Mann) 和尼克·莱恩斯 (Nick Lynes) 创立,它可以在演员的脸部上进行映射,并提供我们在人工智能狂野西部见过的最令人印象深刻的翻译。
Stability AI宣布为其用户友好型聊天机器人Stable Assistant推出两项创新功能,进一步提升用户体验和创造力。这两项新功能分别是图片编辑中的搜索和替换,以及通过Stable Audio生成高质量音频。
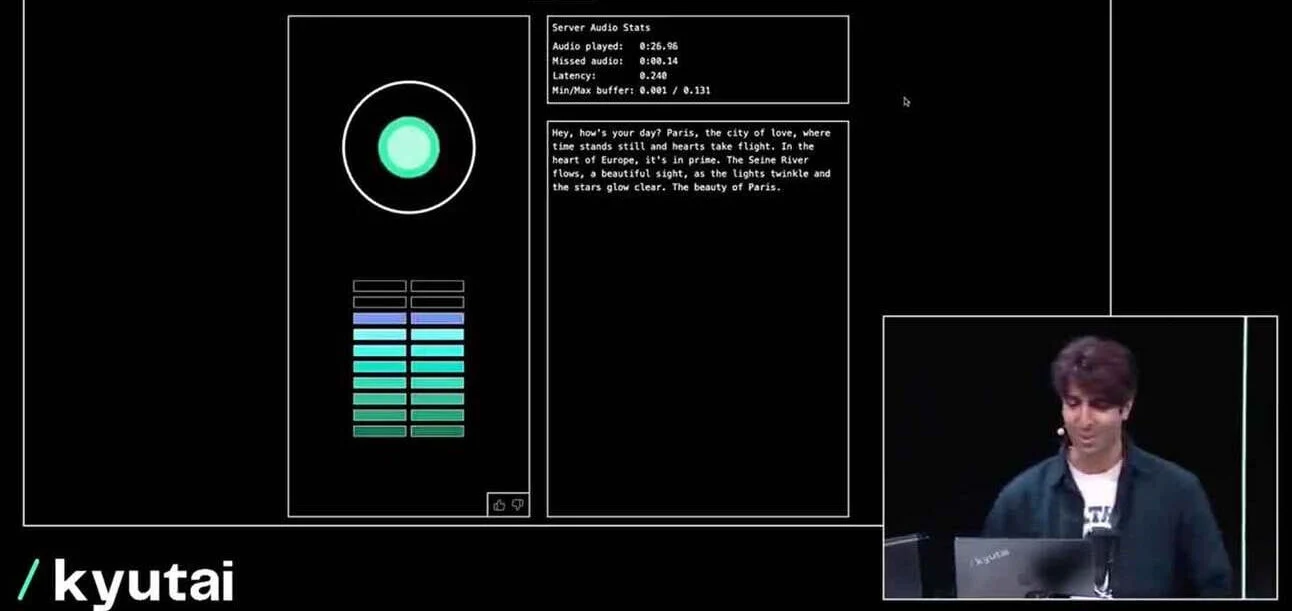
法国独立非盈利AI研究实验室Kyutai推出了具备70种情绪的语音助手Moshi,被视为GPT-4的新挑战者。此次在巴黎的演示显示,Moshi不仅具备多模态交互能力,还能实时生成具有情绪变化的语音,开创性地实现了语音AI的全新应用。
高质量几何生成:生成精细的三维几何形状,用于构建逼真的场景和物体。
写实材质生成:创建高度真实的材质,使得生成的物体看起来更加生动和自然。
惊艳的光照效果:生成和控制光照效果,增强场景的视觉冲击力和氛围。
可控的运动生成:创建和调整动画和运动效果,使得场景和角色更加动态和逼真。
和EMO相比,该项目已开源😄
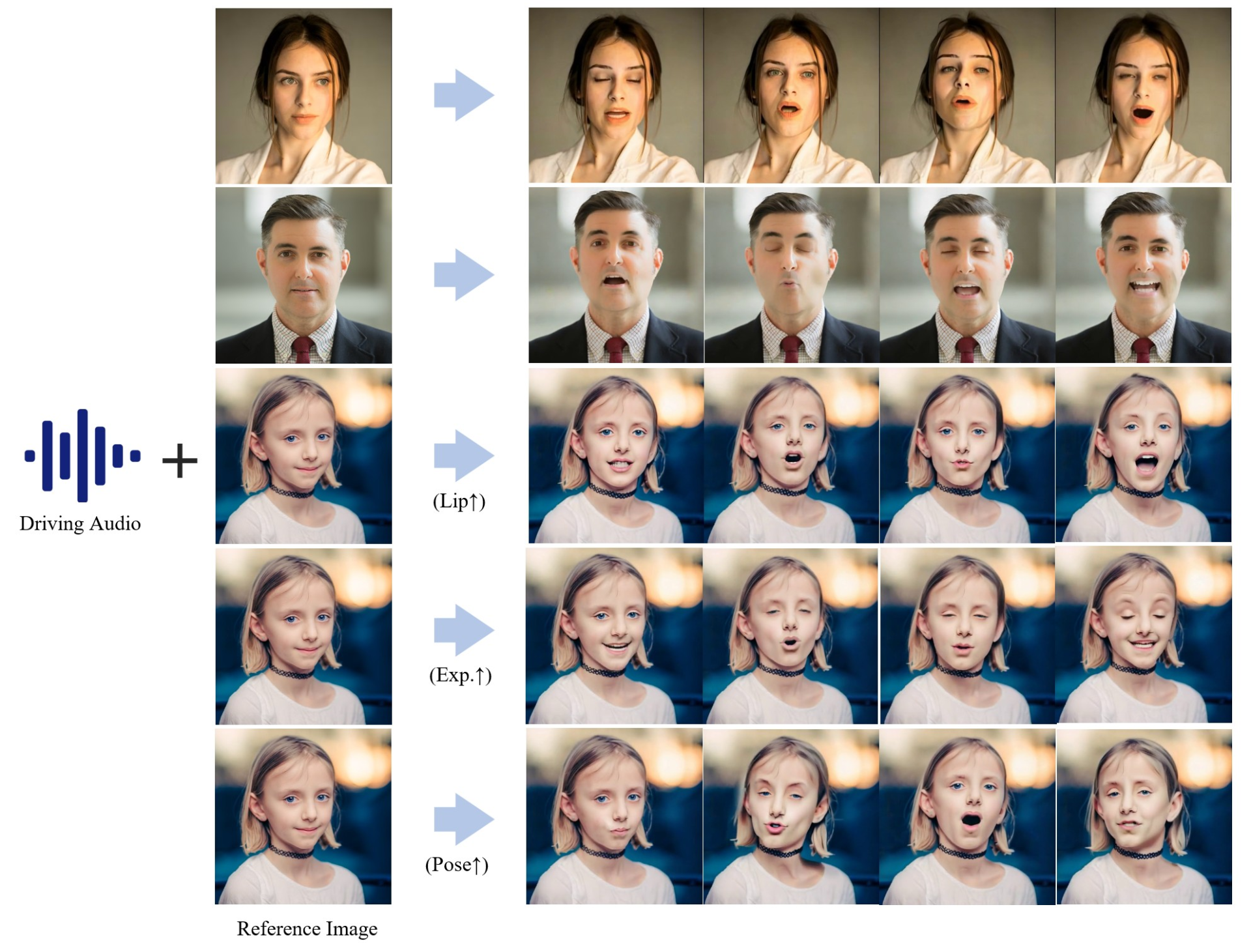
它能够通过输入语音,生成对应的人物嘴唇同步、表情变化和姿态变化的动画。
提高了语音与生成动画之间的对齐精度,使动画的嘴唇、表情和姿态与语音更匹配。
提供对角色表情、姿态和嘴唇运动的精确控制。
支持多种表情和姿态的自适应控制,增强动画的多样性和真实性。
苹果新出的翻译 API,不需要联网,完全使用本机大语言模型。
使用翻译框架提供应用内翻译。您可以使用内置 UI,让系统代表您向用户提供翻译。或者您可以使用该框架来定制翻译体验。
要提供内置系统翻译体验,请将视图修饰符锚定到包含要翻译的文本的 SwiftUI 视图。当您希望显示内置系统翻译 UI 时,将 isPresented 设置为 true。将要翻译的文本传递给 text 参数。
提供了 Colab 笔记,直接运行就可以,不需要摆弄麻烦的 Comfyui 流程和一堆模型了。
Diffutoon 能够以动漫风格渲染出细节丰富、高分辨率和长时间的视频。它还可以通过一个附加模块根据提示编辑内容。
可实现多人、多语言的实时对话翻译
用户可以通过蓝牙耳机连接应用,将手机放进口袋,与他人进行实时语言转换的对话,应用会自动翻译并播报对方的语言。
Gen-3 Alpha是Runway的反击之作。Gen-3 Alpha的一大特点是生成的视频具有高精细度,它可以理解并生成复杂的场景和运动画面,还能胜任多种电影艺术手法。
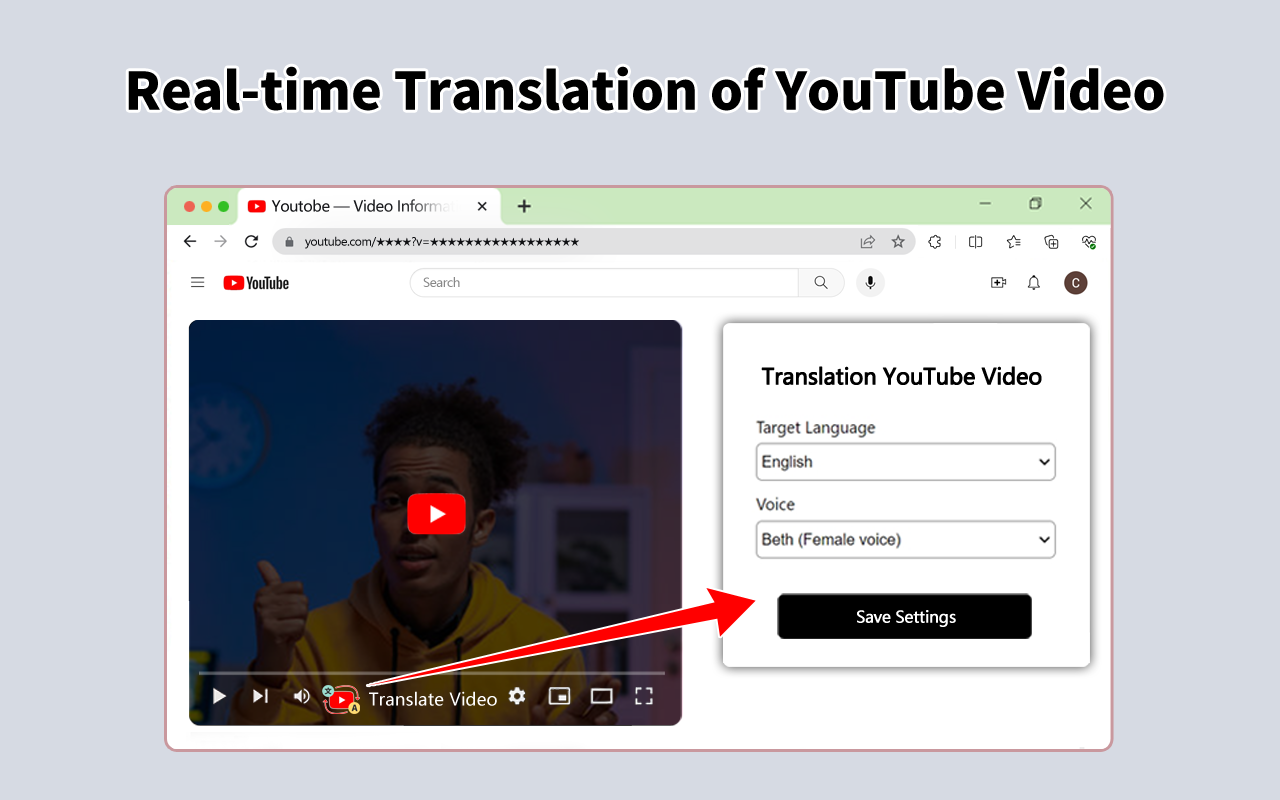
YouTube Dubbing插件,一键将英语视频转换为中文的声音进行播放,非常适合用来看国外教程类的视频,
目前支持Youtube 和Udemy 。PC,Android ,IOS 都支持。
直接在网络浏览器中实现实时语音识别长期以来一直是一个备受追捧的里程碑。 Hugging Face 工程师(昵称“Xenova”)开发的 Whisper WebGPU 是一项突破性技术,利用 OpenAI 的 Whisper 模型实现浏览器内实时语音识别。这一显着的发展是与人工智能驱动的网络应用程序交互的巨大转变。
Luma AI 刚刚推出了一款类似 Sora 的 AI 视频生成器,名为 Dream Machine。
但与 Sora 或 KLING 不同的是,它完全向公众开放。
Truecaller 很自豪地宣布与 Microsoft 建立合作伙伴关系,利用 Microsoft Azure AI Speech 的全新个人语音技术。 Truecaller 的 AI 助手于 2022 年 9 月首次推出,已经融合了多种 AI 技术,可以自动为您接听电话、屏幕呼叫、接收消息、代表您回复或记录通话以供您以后查看。
Seed-TTS,这是一系列大规模自回归文本转语音(TTS)模型,能够生成几乎与人类语音无法区分的语音。
Seed-TTS作为语音生成的基础模型,在语音上下文学习中表现出色,在说话者相似性和自然性方面的表现与真实人类语音在客观和主观评估中相匹配。
通过微调,我们在这些指标上获得了更高的主观评分
ChatTTS:专门为对话场景设计的文本到语音TTS模型
该模型经过超过10万小时的训练,公开版本在 HuggingFace 上提供了一个4万小时预训练的模型。
专为对话任务优化,能够支持多种说话人语音,中英文混合等。
可以将你直播说话时候的声音变声其他各种角色和性别的声音。
还能调整音调、音调动态和混响等参数,塑造个性化的声音。
也可以将你声音与任何角色的声音以任意比例混合,创造出新的声音 。