AI视频剪辑软件:Kurisu
AI视频剪辑
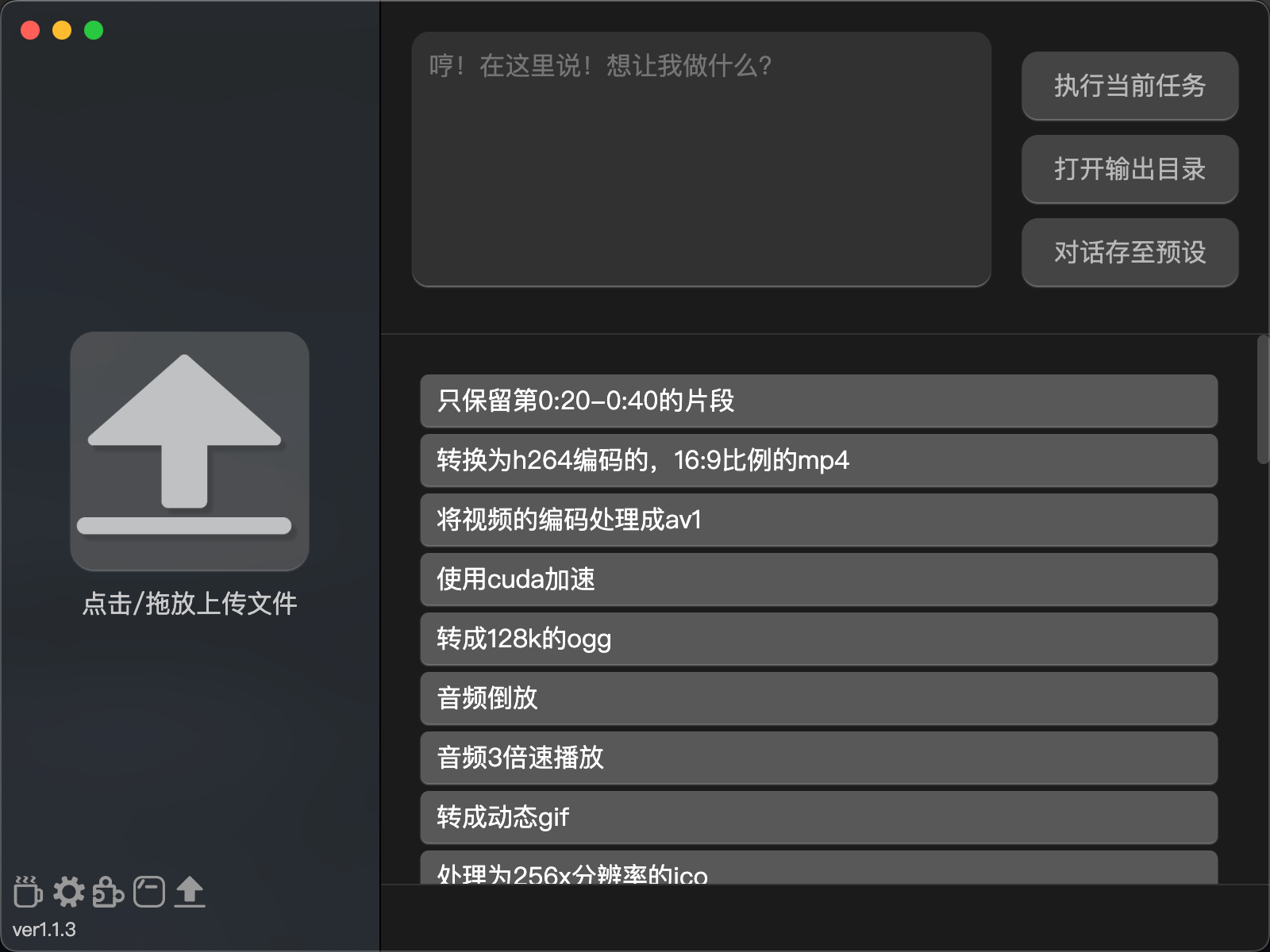
一个靠口头描述来转换文件格式的程序。
字面意思,就是口述。
例如,你拖动或者上传了一份mp4,然后你只需在输入框内描述你想干的内容。 像是“转成webm”“只保留视频第10秒到20秒之间的内容”“提取音频文件”“将视频倒放”这类。 然后点击按钮们等待进度条完成就行。 运用了ChatGPT和FFmpeg的对接。
AI视频剪辑
一个靠口头描述来转换文件格式的程序。
字面意思,就是口述。
例如,你拖动或者上传了一份mp4,然后你只需在输入框内描述你想干的内容。 像是“转成webm”“只保留视频第10秒到20秒之间的内容”“提取音频文件”“将视频倒放”这类。 然后点击按钮们等待进度条完成就行。 运用了ChatGPT和FFmpeg的对接。
Pikimov 是一款基于Web 的应用程序,允许用户创建和编辑各种媒体类型,包括图像、视频、音频和3D 模型。
它为运动设计提供了基于图层的合成系统和关键帧动画系统。
该应用程序与Windows、macOS 和Linux 操作系统兼容,无需任何安装。 所有用户文件都保留在本地计算机上,不会上传到服务器
Canva 已收购澳大利亚 AI 初创公司 Leonardo.ai,获得了其文本转图像和文本转视频生成器的访问权限。此举加强了 Canva 在生成式 AI 市场的地位,有可能挑战 Adobe 的主导地位。
Leonardo.ai 的技术将被整合到 Canva 的 Magic Studio 产品中,而其平台将保持独立运营。此次收购正值 Canva 寻求扩展其创意套件并与 Adobe 的 Firefly 模型竞争之际。然而,Canva 面临对其数据训练实践的审查,需要应对围绕生成式 AI 的伦理问题。
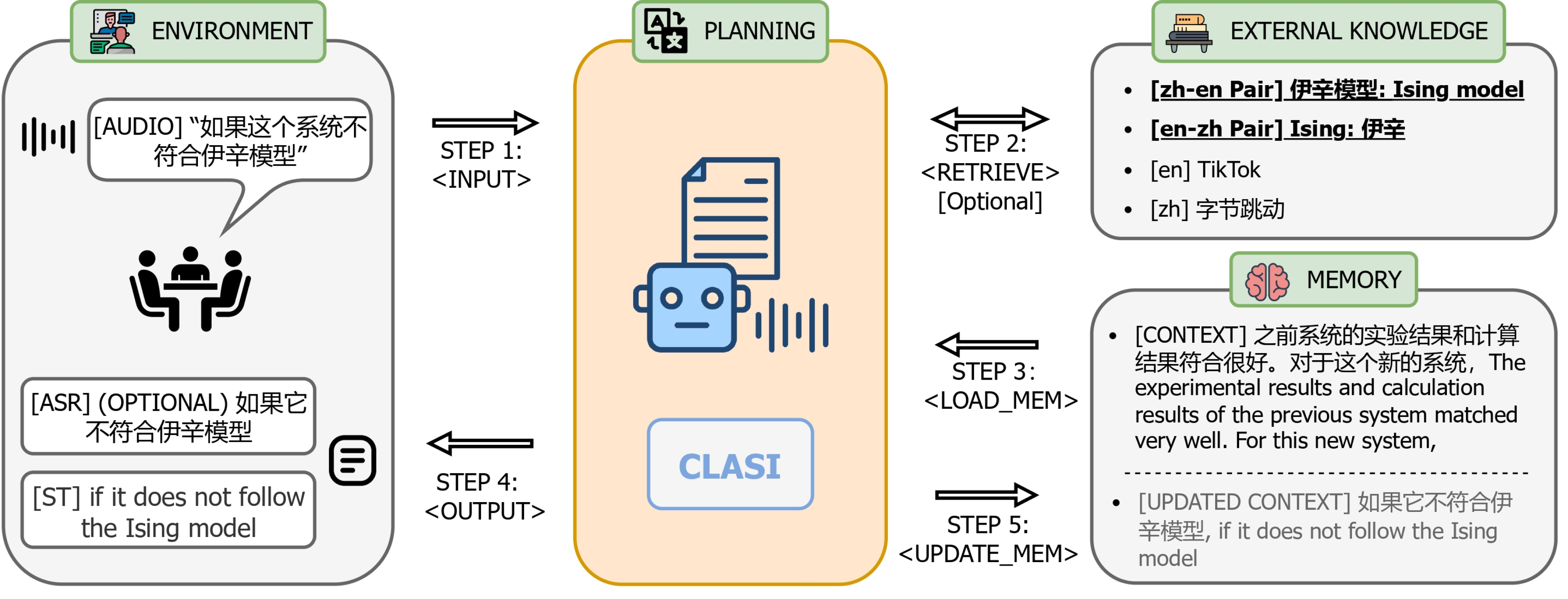
CLASI是由字节跳动开发的一个高质量的同时语音翻译系统,类似于专业的人类译员。它能实时翻译语音内容,保持高翻译质量和低延迟。CLASI利用先进的数据策略和多模态检索技术来处理复杂的术语和不清晰的语音信息。
CLASI会根据当前的音频内容,结合外部知识库和历史上下文,生成准确且容错的翻译。它在各种测试数据集上的表现都非常出色,能够传达更多有效信息。
Vozo Rewrite & Redub 是一款创新的视频编辑工具,你可以通过简单的提示重写视频脚本、然后这个工具会自动给视频重新配音、翻译语音并口型同步,然后生成新的视频。
无论是将经典视频转变为病毒视频宣传片,还是将普通视频变成喜剧,亦或是将一种语言翻译成多种语言,Vozo 都能在几秒钟内完成。
大部分新功能需要订阅标准版才可以用,目前的定价是 10 美元/月
AI 说唱生成器是一款尖端工具,利用先进的人工智能来创作独特的说唱歌曲。无论您是经验丰富的艺术家还是只是想享受乐趣,我们的人工智能说唱生成器都提供了一种无缝的方式来制作个性化的说唱音乐。您可以输入自己的歌词、选择乐器并选择音乐风格,以根据您的喜好精确定制您的说唱歌曲。
它能够感知和表达情感,并根据上下文和人类指令提供多种风格的语音响应,如说唱、戏剧、机器人、搞笑和低语等。
超过10万小时的学术和野外收集的语音数据, 涵盖了丰富的语音场景和风格。
SpeechGPT2 是在有限资源下的技术探索,由于计算和数据资源的限制,它在语音理解的噪声鲁棒性和语音生成的音质稳定性方面仍有一些不足。
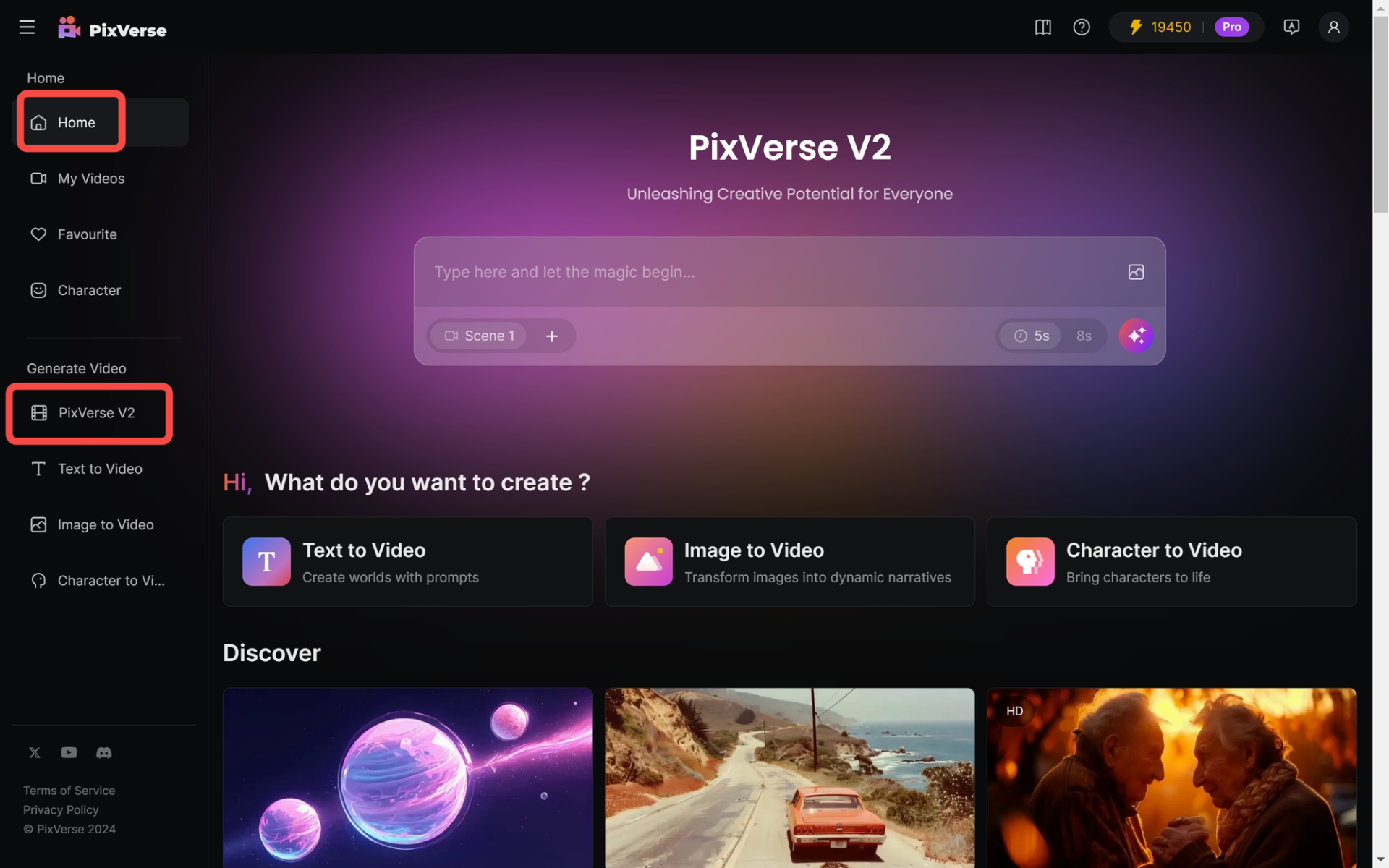
升级版的PixVerse V2,不光能生成8秒的视频,还能让你的创意天花乱坠。
别以为8秒就敷衍了事。这V2可是个细节控,分辨率、动态效果都跟打了鸡血似的。
就连蚂蚁打喷嚏,它都能给你拍得清清楚楚。
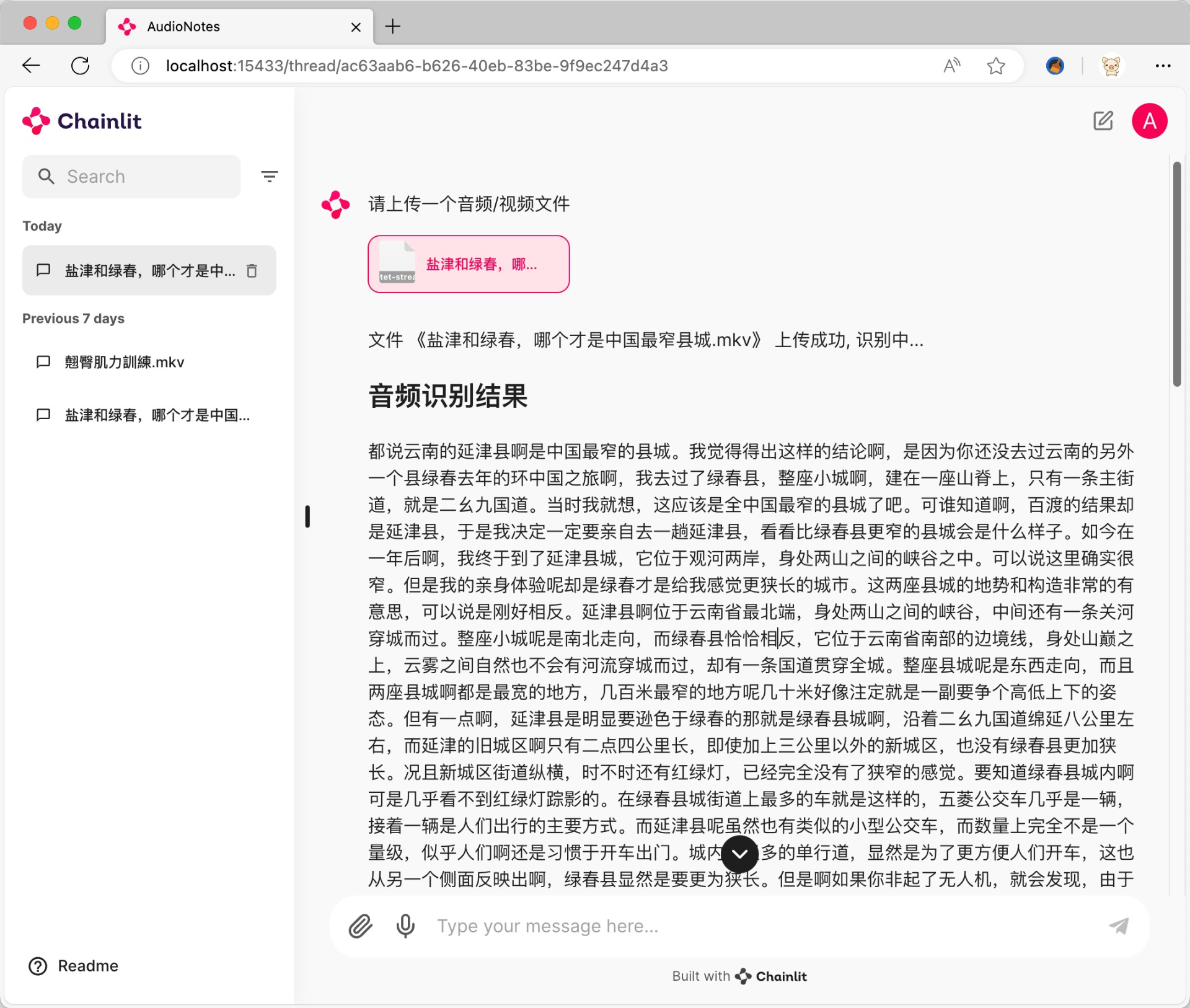
AudioNotes 是一个基于 FunASR 和 Qwen2 构建的音视频内容转结构化笔记系统。它的主要功能是快速提取音视频的内容,并通过调用大模型进行整理,将这些内容转换为结构化的Markdown笔记,便于用户快速阅读和理解。
该模型支持包括普通话在内的 32 种语言,能为全球近 80%的地区提供高质量、低延迟的 AI 对话;
首次支持越南语、匈牙利语和挪威语;
重点提高了印地语、法语、西班牙语、普通话等 27 种语言的响应速度,其中英语速度提高了 25%,最高提升达 3 倍;
结合先进技术和低延迟模型架构,可快速合成语音,保持流畅自然且高品质的音质,响应时间不超 400 毫秒。
港中大(深圳)联合中科院声学所、上海人工智能实验室等机构发布了超过10万小时包含6种语言的多样化的语音生成数据集—— Emilia!
Emilia是一个开源的多语种外语音数据集,专为大规模语音生成研究设计。它包含超过101,000小时的六种语言高质量语音数据和相应的文本转录,覆盖了各种说话风格和内容类型,如脱口秀、访谈、辩论、体育评论和有声书。
etect-2B的子模型由带有关键层插入适配模块的冻结音频表示模型组成。这些适配模块专注于识别真实音频与伪造音频的细微差别——即录音中不经意留下的声音痕迹。大多数AI生成的音频片段听起来都“过于完美”。Detect-2B能够预测音频中AI制作的成分,而且无需每次听到新片段时都重新训练模型。这些子模型也经过了大型数据集的充分训练。
StreamVC 即使在移动平台上也能以低延迟从输入信号生成结果波形,使其适用于呼叫和视频会议等实时通信场景,并解决这些场景中的语音匿名等用例。
谷歌的设计利用 SoundStream 神经音频编解码器的架构和训练策略来实现轻量级高质量语音合成。
谷歌证明了因果学习软语音单元的可行性,以及提供白化基频信息以提高音调稳定性而不泄漏源音色信息的有效性。
RenderNet Al是一款强大的图像生成工具,专注于创建一致的角色,
并控制其姿势、构图和风格,现在推出了视频换脸功能..
这款 AI 视频换脸工具非常强大