AzureOpenAIService宣布了一系列新功能
包括公开预览的Assistants API、新的文本到语音(TTS)功能、即将推出的GPT-4 Turbo和GPT-3.5 Turbo模型更新、新的嵌入模型以及微调API的更新。
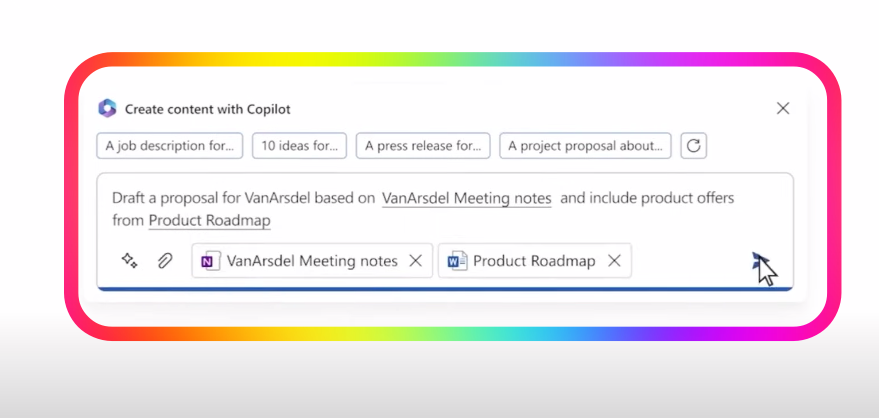
与之前的聊天完成API相比,Assistants API能够记住之前的对话内容,创建持久化和无限长的线程。
Assistants API 是一项由 Azure OpenAI 提供的新服务,它旨在帮助开发者在他们的应用程序中更容易地创建高质量的人工智能助手体验。
包括公开预览的Assistants API、新的文本到语音(TTS)功能、即将推出的GPT-4 Turbo和GPT-3.5 Turbo模型更新、新的嵌入模型以及微调API的更新。
与之前的聊天完成API相比,Assistants API能够记住之前的对话内容,创建持久化和无限长的线程。
Assistants API 是一项由 Azure OpenAI 提供的新服务,它旨在帮助开发者在他们的应用程序中更容易地创建高质量的人工智能助手体验。
模型有1.2亿个参数,经过了10万小时的语音数据训练。
专注英语情感演讲
跨语言语音克隆
支持美国和英国声音的零样本克隆
支持长篇内容语音合成
是通过对OpenAI的Whisper语音识别模型反向工程来实现的。
通过这种反转过程,WhisperSpeech能够接收文本输入,并利用修改后的Whisper模型生成听起来自然的语音输出。
输出的语音在发音准确性和自然度方面都非常的优秀。
可以选择角色和设定,创建独特的AI生成故事。通过AI驱动的故事和个性化练习吸引学生阅读并提高阅读流畅度。
当你阅读时,语音转文本AI分析阅读流利性,检测学习者挑战的词汇,并记录阅读的准确性、速度和时间。
除了文字转语音功能,它还能可以将一首歌的声音换成另一个歌手的声音。还支持声音转换、歌声合成、文本到音频、文本到音乐等功能!
这个模型统一了之前的三个Seamless系列模型,可以实时翻译100多种语言,延迟不到2秒钟,说话者仍在讲话时就开始翻译。
您只需单击 2 次即可生成矢量图并将其导入到 PowerPoint(或 Word)中。
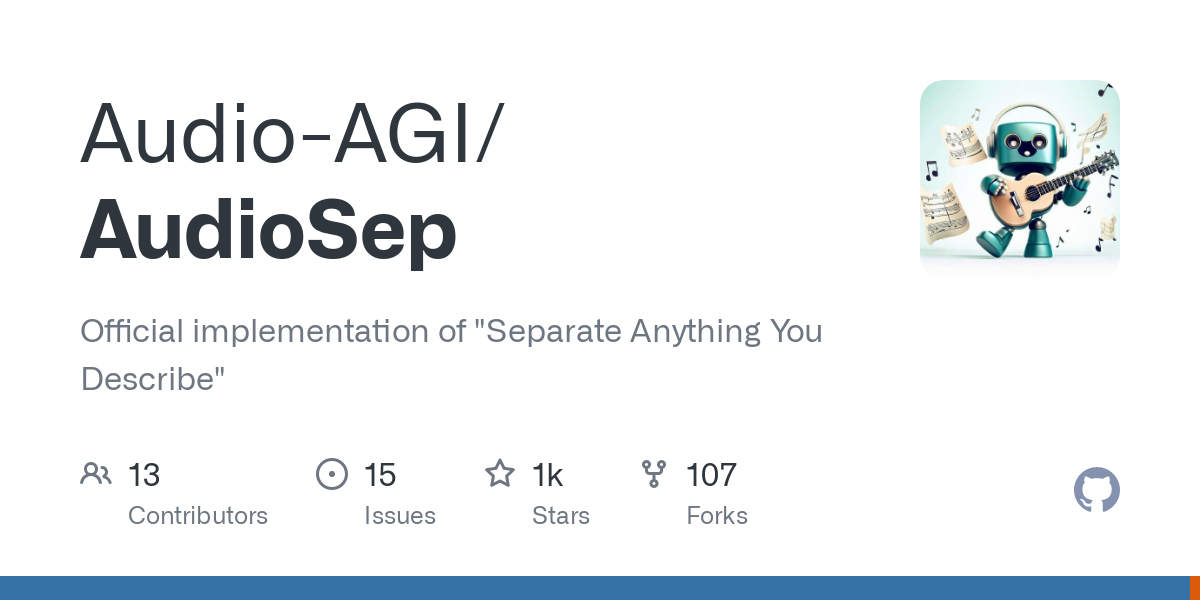
AudioSep可以从任何混合的音频信号中提取出特定的声音成分并分离出来。与传统的声音分离模型不同,AudioSep允许用户通过自然语言描述来指定他们想要分离的声音。
一个为设计师提供的背景去除工具,你只需上传图片,AI就会自动处理剩下的部分,一键去除背景。该工具支持JPG、PNG、WebP格式的图片,并允许一次性上传多达500张图片。